
Cardiovascular
Genetic insights into resting heart rate and its role in cardiovascular disease
Aug
Abstract
Resting heart rate is associated with cardiovascular diseases and mortality in observational and Mendelian randomization studies. The aims of this study are to extend the number of resting heart rate associated genetic variants and to obtain further insights in resting heart rate biology and its clinical consequences. A genome-wide meta-analysis of 100 studies in up to 835,465 individuals reveals 493 independent genetic variants in 352 loci, including 68 genetic variants outside previously identified resting heart rate associated loci. We prioritize 670 genes and in silico annotations point to their enrichment in cardiomyocytes and provide insights in their ECG signature. Two-sample Mendelian randomization analyses indicate that higher genetically predicted resting heart rate increases risk of dilated cardiomyopathy, but decreases risk of developing atrial fibrillation, ischemic stroke, and cardio-embolic stroke. We do not find evidence for a linear or non-linear genetic association between resting heart rate and all-cause mortality in contrast to our previous Mendelian randomization study. Systematic alteration of key differences between the current and previous Mendelian randomization study indicates that the most likely cause of the discrepancy between these studies arises from false positive findings in previous one-sample MR analyses caused by weak-instrument bias at lower P-value thresholds. The results extend our understanding of resting heart rate biology and give additional insights in its role in cardiovascular disease development.
Introduction
Higher resting heart rate (RHR) is associated with cardiovascular diseases and all-cause mortality in traditional epidemiological studies1,2,3,4,5. However, RHR is influenced by disease status and a plethora of potential confounders, which could affect these associations.
A Mendelian randomization (MR) approach, in which genetic variants associated with RHR are used as a proxy for RHR, can also be used to study the association of RHR with cardiovascular diseases and all-cause mortality. Since genetic variants are fixed from conception and then randomly assigned from parents to offspring, they are more immune to reverse causation and confounders6. In our previous study, we found evidence for a positive association between genetically predicted RHR and all-cause mortaliy7. However, a higher genetically predicted RHR was not found to increase the risk of cardiovascular diseases7,8,9 and appeared to decrease the risks of atrial fibrillation and cardio-embolic stroke9. Multiple genome-wide association studies (GWAS) have identified RHR-associated genetic variants which could be used as genetic instruments in MR studies to entangle the relationship between RHR and cardiovascular disease7,8,10. The two largest GWAS to date have been performed in the UK Biobank7,10 but were either performed in a subcohort of individuals with available genetic data during its time of publication7 or lacked a replication cohort10. We set out to perform a genome-wide meta-analysis of RHR in the largest sample size to date with internal replication of the associated genetic variants, in order to broaden our knowledge of the biological mechanisms underlying interindividual differences in RHR and identify robustly associated RHR-associated genetic variants to assess the genetic association of RHR with cardiovascular disease and all-cause mortality.
In this work, a genome-wide meta-analysis of 100 studies in up to 835,465 individuals reveals 493 independent RHR-associated genetic variants in 352 loci, including 68 genetic variants outside previously identified RHR-associated loci (Fig. 1a). In addition, in silico analysis pinpoint that identified candidate genes are mainly enriched in cardiomyocyte tissue (Fig. 1b), and Mendelian randomization analyses indicate that higher genetically predicted resting heart rate is not associated with all-cause mortality, increases the risk of dilated cardiomyopathy, but decreases the risk of developing atrial fibrillation, ischemic stroke, and cardio-embolic stroke (Fig. 1c).
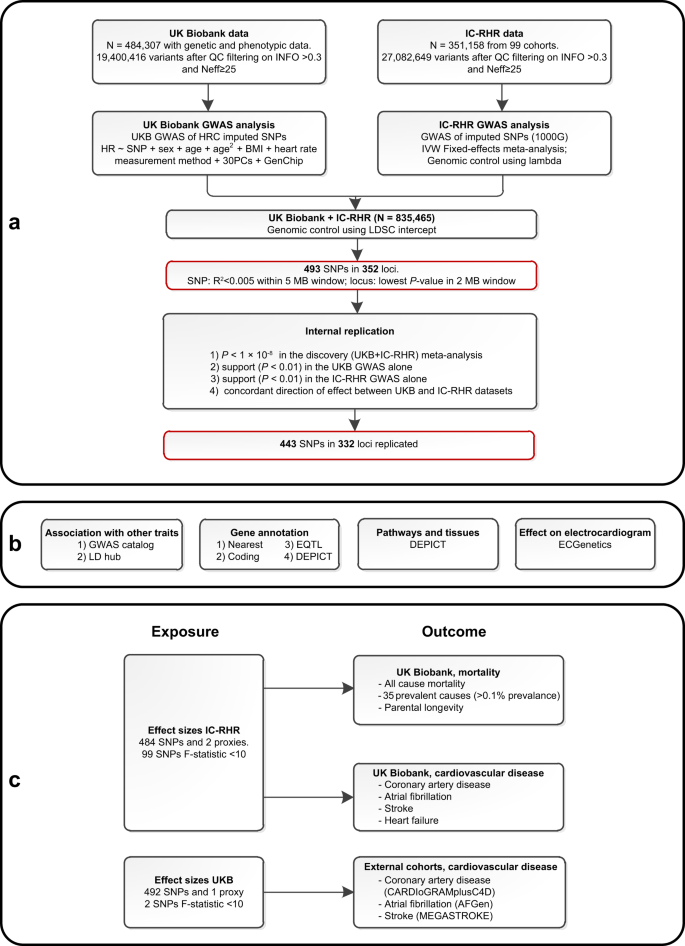
a Schematic overview of the study design for the discovery and replication of genetic loci associated with resting heart rate (RHR) using mixed linear models with a two-sided P-value of P < × 10−8 to define genome-wide significance. A genome-wide significant genetic variant was considered replicated if P < 0.01 in the UK Biobank and IC-RHR cohort with concordant effect sizes. The black-bordered boxes show the methodology, the red-bordered boxes show the most important results. b Analyses performed to evaluate RHR-associated genetic variants and to gain further insights into the underlying biology. c Schematic presentation of the two-sample Mendelian randomization analyses of genetically predicted RHR on mortality and cardiovascular diseases. Effect sizes were taken from the IC-RHR data to test the associations with mortality and cardiovascular diseases in the UK Biobank. Effect sizes were taken from the UK Biobank to test the association with coronary artery disease and myocardial infarction in the CARDIoGRAMplusC4D cohort, atrial fibrillation in the AFGen cohort, and any, ischemic, cardio-embolic, large artery and small vessel stroke within the MEGASTROKE consortium. BMI body mass index, GWAS genome-wide association study, HRC Haplotype Reference Panel, IC-RHR International Consortium for Resting Heart Rate, MB megabase, N sample size, Neff effective sample size, PC principal components, RHR resting heart rate, SNPs single nucleotide polymorphisms, QC quality control, 1000G = 1000 Genomes.
Results
Genome-wide meta-analysis of resting heart rate
We performed a meta-analysis of RHR GWAS using 99 cohorts consisting of up to 351,158 individuals, which from here on will be referred to as the International Consortium of Resting Heart Rate (IC-RHR). Second, we performed a GWAS on 484,307 individuals from the UK Biobank. These large cohorts were meta-analyzed to include up to 835,464 individuals, in whom 30,458,884 directly genotyped and imputed autosomal variants were analyzed (Supplementary Data 1, Fig. 1a). The meta-analysis revealed 493 independent genetic variants in 352 loci. Out of these 493 independent genetic variants, 68 were outside previously identified RHR-associated loci and 67 of those were internally replicated (Fig. 2a, Supplementary Data 2)7,8,10. Out of the 425 genetic variants inside previously identified RHR-associated loci, a total of 376 were internally replicated. In addition, 332 out of the 352 loci were considered internally replicated as they showed the concordant direction of effects and nominal associations (P < 0.01) in the UK Biobank GWAS and IC-RHR meta-analysis (Fig. 2b). The RHR-associated genetic variants identified previous studies from Eppinga et al. and Den hoed et al. were all replicated in the current study (Supplementary Data 3). A total of 74 loci identified in the study by Guo et al. were not replicated in the current study, of which 40 would not have been identified as loci using the current GWAS clumping criteria. The remaining 34 loci did not reach genome-wide significance in the current meta-analysis with generally high P-values in the IC-RHR consortium, probably therefore failing replication (Supplementary Data 3). The linkage disequilibrium (LD) score regression intercept of the meta-analysis was 1.051 ± 0.002, suggesting little evidence of genomic inflation (Fig. 2c). The QQ plots for the UK Biobank GWAS and IC-RHR meta-analysis are shown in Supplementary Fig. 1. The genomic control lambda’s, LD-Score intercepts and the attenuation ratio statistics suggested no inflation due to non-polygenic signals11,12. Single nucleotide polymorphism (SNP) heritability of RHR, as calculated by LD score regression, was estimated to be 10%. A polygenic score weighted by the effect sizes of the IC-RHR explained 5.33% of the variation in RHR in the UK Biobank. A Chow test indicated the absence of strong differences between participants with a history of any cardiovascular disease or use of RHR-altering medication versus participants without such a medical history (Supplementary Data 4). Genetic correlation analyses were performed and we observed significant correlations with anthropometric measurements, pulse wave reflection index, and physical activity measurements (Supplementary Data 5). A query of the GWAS Catalog showed that the 493 genetic variants associated with RHR were most commonly in high LD (LD > 0.8) with anthropometric measurements and blood pressure traits (Supplementary Data 6).

a Manhattan plot showing the −log10(P-value) for the association of all genotyped or imputed genetics variants with resting heart rate (RHR) assessed using mixed linear models. Red indicates novel and internally replicated RHR-associated loci and black indicates novel but unreplicated RHR-associated loci. Dark gray indicates RHR-associated genetic variants within 1 MB of previously identified RHR-associated loci, which were internally replicated in the current study. Light gray indicates RHR-associated genetic variants within 1 MB of previously identified RHR-associated loci, which were not internally replicated in the current study. A two-sided P-value of P < 1 × 10−8 was used to define genome-wide significance. A genome-wide significant genetic variant was considered replicated if P < 0.01 in the UK Biobank and IC-RHR cohort with concordant effect sizes. b Venn diagram of the 352 identified loci. Of the 352 loci, 332 were internally replicated. c Quantile–quantile (QQ) plot of the final meta-analysis. The black dots represent the observed statistic for the genotyped genetic variants against the corresponding expected statistic. The linkage disequilibrium score regression intercept after the final meta-analysis was 1.051, suggesting little evidence of genomic inflation due to non-polygenic signal. d Venn diagram of the prioritization of the 670 unique candidate causal genes as identified by one or multiple strategies. Venn plot shows the overlap of genes tagged by one or multiple strategies, including (1) by proximity, the nearest gene or any gene within 10 kb; (2) genes containing coding variants in LD with RHR-associated variants at R2 > 0.8; (3) eQTL genes in LD (R2 > 0.8) with RHR-associated variants which achieved a Bonferroni corrected two-sided P = 2.65 × 10−7 and passed the HEIDI test at a P > 0.05; and (4) DEPICT genes which achieved multiple hypotheses corrected FDR < 0.05. DEPICT data-driven expression prioritized integration for complex traits, eQTL expression quantitative trait loci.
Candidate genes and insights into biology
We explored the potential biology of the 352 RHR-associated loci by prioritizing candidate genes in these loci (Supplementary Data 2). A total of 407 unique genes were in close proximity to the lead variant, defined as the nearest gene and any additional gene within 10 kb (Supplementary Data 2). There were 52 genes that contained coding genetic variants in LD (R2 > 0.80) with RHR lead variants. Functional annotation of these coding variants is provided in Supplementary Data 7. Using summary data-based Mendelian randomization analysis (SMR) and heterogeneity in dependent instruments (HEIDI) tests, we found that the RHR-associated loci and eQTLs colocalized at 88 genes (Supplementary Data 8)13. Lastly, 381 unique genes were taken forward by data-driven expression-prioritized integration for complex traits (DEPICT) analyses (Supplementary Data 9). Of the 670 unique candidate causal genes identified, 33 genes were prioritized by at least three out of four established methods, which may be used to prioritize candidate genes (Fig. 2d). Of these genes, PHACTR4, ENO3, and SENP2 were prioritized by all four methods. Full annotations of all identified genes are in Supplementary Data 10.
Pathway analyses and tissue enrichment
Pathway analysis performed by DEPICT showed that RHR revolved around mainly cardiac biology, including cardiac tissue development, muscle cell differentiation, and pro-arrhythmogenic pathways. A total of 1471 reconstituted gene sets within 155 gene clusters were significantly associated with RHR (FDR < 0.05). The newly discovered gene clusters consisted of mostly protein–protein interaction pathways and were commonly located in the periphery of the network (Supplementary Data 11, Supplementary Fig. 2). The tissue enrichment analysis by DEPICT showed 28 tissues at FDR < 0.05 and implicated the cardiovascular system as the most important tissue type, with 8 of the 10 most significantly enriched tissues located within the cardiovascular system (Fig. 3, Supplementary Data 12). Non-cardiovascular tissues with enrichment included muscle and fat tissues, the adrenal glands, the esophagus, and urogenital structures. Conditional analyses showed that associations with non-cardiovascular tissues were rather due to co-expression of RHR genes in cardiovascular tissue than independent enrichment of RHR-associated genes in non-cardiovascular tissues (Fig. 3).

a Results of the DEPICT tissue enrichment analysis. The Y-axis shows the tissues clustered by the first MeSH term, ordered on Z-value per cluster. The X-axis shows the Z-value. A multiple comparisons corrected two-sided FDR < 0.05, corresponding to a P-value < 9.75 × 10−3 and Z-value of 2.585, was considered to be statistically significant. Significant tissues are plotted in red and annotated, other tissues are plotted in gray. Conditional analyses were performed by correcting for the tissue with the highest Z-value to investigate whether significant tissues were independently associated with RHR. Not a single tissue remained significant at an FDR < 0.05 after three consecutive corrections (for the heart, heart valve, and arteries). Panel b–d shows Z-values of all tissues after consecutive correction for respectively heart and heart valves, heart and arteries, and heart valve and arteries. This jointly provides information on which the other tissues are co-dependent. FDR false discovery rate.
ECG morphology
The ECGenetics browser, which contains genome-wide summary statistics of every time-point of the complete cardiac cycle at a resolution of 500 Hz, was used to gain insights into the electrophysiological effect of the RHR genetic variants14. A total of 86 genetic variants were strongly associated with at least one ECG time point on the non-normalized and normalized association patterns across the full RR interval at a stringent Bonferroni-corrected P-value < 1 × 10−7. The associations represented a plethora of ECG morphologies (Supplementary Data 13, Supplementary Fig. 3). The ACHE, ANKRD1, and SCN5A genes exhibited their largest electrical effects on atrial depolarization, BAG3 and TTN on ventricular depolarization, and RGS6 and SYT10 on ventricular repolarization. The ECG-wide MR highlighted several loci that had not been associated with resting heart rate or cardiac rhythm and structure previously. The CCLN1 gene exhibited strong effects on atrial depolarization, RAP1A and ZBTB38 exerted strong effects on early and late ventricular repolarization, respectively. The ECG-wide MR showed that RHR variants exert the largest effect on ventricular repolarization on both the non-normalized and normalized association patterns (Supplementary Fig. 4).
Single-nucleus RNA expression
Single-nucleus RNA sequencing data obtained from a healthy human heart revealed that RHR gene expression is highest in ventricular cardiomyocytes, followed by atrial cardiomyocytes (Supplementary Data 14)15. The candidate genes of genetic variants involved in non-isoelectric parts of the ECG showed stronger expression patterns than the isoelectric parts, for example, those involved in left atrial depolarization (ANKRD1), ventricular depolarization (FOHD3, RBM20, MYO18B, TTN) and ventricular repolarization (CACNA1C) (Supplementary Fig. 3).
Mendelian randomization analyses
Series of two-sample MR analyses were performed to test whether genetically predicted RHR is associated with all-cause mortality and cardiovascular diseases (definitions provided in Supplementary Data 15, 16). We initially used the inverse variance weighted multiplicative random-effects (IVW-MRE) model, which provides a consistent estimate under the assumption of balanced pleiotropy. If we found evidence for a genetic association using the IVW-MRE model, we further interrogated these findings using several sensitivity analyses that are more robust to different sources of bias in MR analyses.
First, we assessed the association between genetically predicted RHR and all cause-mortality in the UK Biobank participants over a median follow-up of 8.9 years (interquartile range 8.2–9.5) (Supplementary Data 17–19). Genetically predicted RHR was not associated with the risk of all-cause mortality (HR 1.024, 95% CI 0.993–1.057, P = 0.13), as shown in Fig. 4a. We did not find evidence for an association between genetically predicted RHR and parental longevity. Neither did we find evidence for an association between RHR and the 35 leading causes of mortality in the UK Biobank. Systematic alteration of key differences between the current and previous Mendelian randomization study indicated that the most likely cause of the discrepancy between these studies arises from false positive findings in previous one-sample MR analyses caused by weak-instrument bias at lower P-value thresholds (Supplementary Fig. 5, Supplementary Data 20)7. Non-linear MR analysis showed an always-increasing dose–response relation between genetically predicted RHR and all-cause mortality that was compatible with a null effect (Fig. 4b, Supplementary Data 21, 22), providing no evidence for a U-shaped pattern that has been previously described3.

Linear and non-linear Mendelian randomization analyses were performed to test the association between genetically predicted RHR and all-cause mortality. a Forest plot of the linear MR analyses between genetically predicted RHR and all-cause mortality (Ncases = 16,289, Ncontrol = 396,183). With a single outcome, a two-sided P-value of P < 0.05 was considered significant. Hazard ratios and 95% confidence intervals are shown. The X-axis shows hazard ratio’s on a log10 scale, the center as indicated by a gray line depicts a hazard ratio of 1. b Dose–response curve of the non-linear MR analyses between genetically predicted RHR and all-cause mortality (Ncases = 16,039, Ncontroles = 394,144). The comparisons are conducted within strata and therefore the graph provides information on the expected average change in the outcome if a person with an RHR of (say) 70 bpm instead had an RHR value of 90 bpm. The gradient at each point of the curve is the localized average causal effect. Shaded areas represent 95% confidence intervals. With a single outcome, a two-sided fractional polynomial non-linearity P-value of P < 0.05 was considered significant. The X-axis shows RHR, the Y-axis shows hazard ratios. The center as indicated by a dark gray line depicts a hazard ratio of 1. RHR resting heart rate, HR hazard ratio, CI confidence interval, MR Mendelian randomization, IVW inverse variance weighted, FE fixed effects, MRE multiplicative random effects.
We then explored the association between genetically predicted RHR and several prevalent cardiovascular diseases. We did not find evidence for an association between genetically predicted RHR and coronary artery disease in the UK Biobank (OR 0.977, 95% CI 0.946–1.009, P = 0.16) or in the CARDIoGRAMplusC4D cohort (OR 0.976, 95% CI 0.944–1.010, P = 0.17), in line with previous analyses8,9. Similarly, there was no evidence for an association between genetically predicted RHR and myocardial infarction in the UK Biobank or in the CARDIoGRAMplusC4D cohort (Fig. 5, Supplementary Data 23–26). We found no evidence for non-linear dose-response relations of genetically predicted RHR with coronary artery disease or myocardial infarction (Supplementary Data 21, 22).

Forestplots of the linear Mendelian randomization analyses of resting heart rate (RHR) on cardiovascular diseases. Effect sizes were taken from the IC-RHR data to test the associations with mortality and cardiovascular diseases in the UK Biobank (panel a). Effect sizes were taken from the UK Biobank to test the association with cardiovascular diseases in the CARDIoGRAMplusC4D, AFGen, and MEGASTROKE consortia (panel b). Results of the MR-IVW, outlier-robust MR-Lasso, and plurality valid MR-Mix are provided. Sample sizes vary per outcome and per cohort and are shown in the figure. Odds ratios and 95% confidence intervals are shown. The X-axis shows odds ratio’s on a log10 scale, the center as indicated by a gray line depicts an odds ratio of 1. RHR resting heart rate, MR Mendelian randomization, IVW inverse variance weighted multiplicative random effects, OR odds ratio, CI confidence interval.
Higher genetically predicted RHR was suggestively associated with a lower risk of atrial fibrillation development in the UK Biobank (OR 0.946, 95% CI 0.897–0.998, P = 0.04) and in the AFgen consortium (OR 0.942, 95% CI 0.897–0.989, P = 0.02), but these results were not significant after correction for multiple testing (P < 4.17 × 10−3). MR-Lasso, which can provide evidence for potential causal associations when there is a small number of genetic variants with heterogeneous ratio estimates, indicated that genetically predicted RHR was significantly inversely associated with atrial fibrillation (Fig. 5, Supplementary Data 23). The contamination mixture model, which provides evidence for potential causal associations if the plurality of the genetic instruments is valid, provided evidence for a negative association between genetically predicted RHR and atrial fibrillation in the UK Biobank cohort, but this was not replicated in the AFgen consortium (Fig. 5). Non-linear MR analyses showed a significant negative exponential growth pattern in the dose-response relation between genetically predicted RHR and atrial fibrillation (Supplementary Data 21, 22, Supplementary Fig. 8). Specifically, individuals at the extreme right tail of the distribution of genetically predicted RHR had a lower risk of atrial fibrillation. For example, compared with the population mean RHR of approximately 70 bpm, individuals with a genetically predicted RHR of 89 and 98 bpm had a significantly lower risk of atrial fibrillation (OR 0.969, 95% CI 0.941–0.998, P = 0.04; OR 0.922, 95% CI 0.897–0.948, P = 6.36 × 10−9), while this was not true for a genetically predicted RHR of 80 bpm (OR 1.000, 95% CI 0.968–1.034, P = 0.99).
We found that higher genetically predicted RHR is associated with the risk of any stroke (OR 0.951, 95% CI 0.926–0.976, P = 1.59 × 10−4), ischemic stroke (OR 0.940, 95% CI 0.915–0.967, P = 1.08 × 10−5) and cardio-embolic stroke (OR 0.875, 95% CI 0.828–0.925, P = 2.11 × 10−6), suggestively associated with large artery stroke (OR 0.939, 95% CI 0.884–0.998, P = 0.04) and not with small vessel stroke (OR 1.001, 95% CI 0.950–1.055, P = 0.97) in the MEGASTROKE consortium. The results were consistent across MR methods for any, ischemic and cardioembolic stroke (Fig. 5, Supplementary Data 23). The associations between genetically determined RHR and any stroke or ischemic stroke could not be replicated in the UK Biobank using a univariable MR IVW-MRE approach (OR 0.987, 95% CI 0.953–1.023, P = 0.49; OR 0.970, 95% CI 0.928–1.015, P = 0.19). We found no evidence for a non-linear association between genetically determined RHR and any ischemic stroke (Supplementary Data 21, 22). We used a multivariable MR approach to gain insights into potential mediating factors or pleiotropic pathways in the association between genetically predicted RHR and stroke. First, we found that the direct effects of RHR on cardio-embolic stroke to be attenuated by the effects of atrial fibrillation and estimated the attenuation through atrial fibrillation to be 18.4% (Fig. 6, Supplementary Data 27, 28). The direct effects of genetically predicted RHR on any stroke and ischemic stroke were most strongly attenuated by pulse pressure, with estimated attenuation of 28.1% and 31.5%, respectively (Fig. 6a, b, Supplementary Data 27, 28). There was a strong association between genetically predicted RHR and pulse pressure (β = −0.192, SE = 0.019, P = 1.81 × 10−24), but MR-Steiger sensitivity analysis filtered a large part of the genetic variants and repeating the MR on the remaining subset did not show a significant association between RHR and pulse pressure (β = −0.005, SE = 0.008, P = 0.57, Supplementary Data 29, 30).

Forestplots of the results of the two-sample multivariable Mendelian randomization analyses of resting heart rate on a any stroke (Ncases = 67,162; Ncontrols = 454,450), b ischemic stroke (Ncases = 60,341; Ncontrols = 454,450) and c cardio-embolic stroke (Ncases = 9006; Ncontrols = 403,807), when using atrial fibrillation, systolic, diastolic and pulse pressure as secondary exposures. Shown in red are the univariable Mendelian randomization estimates which represent the total estimates of resting heart rate on the outcome. In black are the multivariable Mendelian randomization estimates, which show the direct effect of RHR when corrected for the secondary exposure. These results indicate that atrial fibrillation attenuates the beneficial effect of a higher resting heart rate on cardio-embolic stroke, while pulse pressure attenuates the beneficial effect on any ischemic stroke. MR-Steiger sensitivity analysis indicated that the association between the RHR-associated genetic variants and pulse pressure is unlikely mediated through RHR entirely and biological pleiotropic effects are therefore more likely to cause the attenuation of the association between RHR and stroke when correcting for pulse pressure. Odds ratios and 95% confidence intervals are shown. The X-axis shows odds ratio’s on a log10 scale, the center as indicated by a gray line depicts an odds ratio of 1. RHR resting heart rate; MV multivariable, Nsnp number of SNPs.
Lastly, we found that genetically predicted RHR is associated with an increased risk of dilated cardiomyopathy in the UK Biobank (OR 1.391, 95% CI 1.205–1.605, P = 6.27 × 10−6). The results were robust to MR-Lasso (OR 1.411, 95% CI 1.228–1.622, P = 1.20 × 10−6) and MR-contamination mixture models (OR 1.697, 95% CI 1.318–2.184, P = 4.03 × 10−5). We excluded 96 variants associated with the Q-R upslope at −18 ms of the R peak (P < 0.05), which has been established as a biomarker for dilated cardiomyopathy14, to investigate whether reversed causation contributed to the association with dilated cardiomyopathy. The results were similar to the main analyses (Supplementary Table 1). We did not find evidence for an association between genetically predicted RHR and heart failure, heart failure excluding cardiomyopathies, and hypertrophic cardiomyopathy (Fig. 5, Supplementary Data 23). We did not find evidence for a non-linear association between genetically determined RHR and any type of heart failure (Supplementary Data 21, 22). Scatterplots and dose-response curves of the association between RHR and all assessed outcomes can be found in Supplementary Figs. 6–10.
We assessed whether the Wald estimates between the RHR-associated genetic variants and the cardiovascular diseases could identify risk loci not anticipated to be associated with these outcomes in the outcome GWASs. The locus FOXC1 for coronary artery disease, USP39 for myocardial infarction, and SLC35F1 and SSPN for atrial fibrillation were significantly (P < 1.01 × 10−4) and concordantly associated with their respective outcomes in both cohorts while not reaching genome-wide significance in either one of the outcome cohorts (Supplementary Data 31).
Discussion
We report 493 genetic variants in 352 loci associated with RHR, discovered in the largest GWAS meta-analysis of RHR to date in up to 835,465 individuals7,8,16,17. This increase in sample size allowed us to report 68 novel RHR-associated genetic variants and, importantly, provide internal replication for 376 genetic variants previously associated with RHR. A total of 670 candidate genes were prioritized, providing a comprehensive data catalog for future studies on RHR and offering potential new insights into its biology. Four strategies were employed to prioritize candidate genes and PHACTR4, ENO3, and SENP2 were highlighted by all four strategies. The PHACTR4 gene regulates protein phosphatase 1 which interacts with actin and is involved in processes ranging from angiogenesis to cell cycle regulation18. It has been associated with pulse pressure and systolic blood pressure in a previous GWAS analysis19. ENO3 encodes beta-enolase, which plays an important role in glycolysis and striated muscle development20. It has been implicated in cardiac myocyte development through its function in energy metabolism in both humans and rats21,22. SENP2 encodes sentrin-specific protease 2, which deconjugates small ubiquitin-related modifiers 1 and 2 that are involved in regulating posttranslational modification of a wide variety of proteins that affect a multitude of different cellular processes23,24. Several of these affected proteins are critical in cardiac development and mouse models have shown that alterations in SENP2 activity lead to congenital heart defects25,26. Involvement of SENP2 in a multitude of cellular processes is reflected by its implication in GWAS of various conditions, including systolic and diastolic blood pressure27, type 2 diabetes28, the conduction system of the heart29,30 and estimated glomerular filtration rate31. The loci we associated with coronary artery disease (FOXC1), myocardial infarction (USP39), and atrial fibrillation (SLC35F1 and SSPN) through their effects on RHR have been associated with these cardiovascular diseases in recent studies32,33,34,35.
To obtain further biological insights into RHR, we performed pathway analyses using DEPICT and found numerous newly associated pathways. The strongest associated clusters were identified previously and their importance to RHR biology was therefore validated in the current study7. Conditional analyses on the tissue enrichment demonstrate that genes influencing RHR are more likely co-expressed than primarily or solely located within non-cardiovascular tissues. However, it should be noted that conditional analyses inherently attenuate tissue enrichment considering DEPICT is based on the co-regulation of gene expression36. Using cardiac single-nucleus RNA data, we demonstrate that RHR genes are mostly expressed in cardiomyocytes. We provide electrophysiological insights into the biology of the RHR-associated variants and show that they exert diverse effects on ECG morphology with the largest effect on ventricular repolarization.
In-depth analyses were performed to assess genetic associations of RHR with clinical outcomes. In contrast to previous observational1,2 and MR studies7, we do not find evidence for an association between genetically predicted RHR and all-cause mortality. Moreover, genetically predicted RHR was not associated with parental longevity nor with any of the 35 leading causes of mortality. Lack of such associations suggests that follow-up length or large heterogenetic effects of RHR on different causes of mortality are unlikely causes for the absence of an association between genetically predicted RHR and all-cause mortality37. We demonstrate that the most likely cause of the discrepancy between current and previous results arises from false positive findings in previous one-sample MR analyses that were caused by weak-instrument bias at lower P-value thresholds38. We hypothesize that RHR is not on the causal pathway to mortality itself and that previous observational studies are more likely to reflect confounders, such as stress and socio-economic status, or reversed causation, in which an individual’s disease status increases both RHR and mortality risk39,40.
The linear MR between RHR and atrial fibrillation provided suggestive evidence for an inverse relationship between RHR and atrial fibrillation, in line with a previous linear MR study9. We do find a significant negative exponential dose-response curve between RHR and atrial fibrillation in support of an inverse relationship, and take the non-linear MR forward as the main result considering the fractional polynomial test indicated that a non-linear model fitted the localized average causal effect estimates better than the linear model. Previous observational studies on the relationship between RHR and atrial fibrillation have shown conflicting results and have described various relationships including inverse linear41,42,43, U-shaped43, and J-shaped44 associations. All these association patterns support the hypothesis that individuals with a low RHR might exhibit a higher risk of atrial fibrillation development compared to those with an average RHR. A recent stratified Mendelian randomization showed an inverse genetic relationship between RHR and atrial fibrillation in individuals with an RHR below 65 bpm as well45. Possible mechanisms that could underly an increased risk of atrial fibrillation in individuals with a low RHR include increased left atrial stroke volume and consequent atrial remodeling due to myocyte stretching46, or an increased vagal tone promoting global disorganization in the left atrium due to increased heterogeneity of the refractory period47. In contrast to the often hypothesized U-shaped or J-shaped association43,44, we find a decreasing risk of atrial fibrillation development in those with a high RHR. One potential explanation is that previous observational studies were affected by collider bias through confounding factors which increase atrial fibrillation risk and typically occur in tandem with a high rather than a low RHR, such as hypertension48 and obesity49. We advocate for a cautious interpretation of current results due to the diverse biological mechanisms through which the RHR-associated genetic variants alter the risk of atrial fibrillation development8.
We found that genetically predicted RHR was inversely associated with risk of any, ischemic and cardio-embolic stroke. The results were not replicated in the UK Biobank, possibly due to the substantially lower amount of cases. The inverse association is in contrast to many observational studies and we therefore performed multivariable MR analyses to pinpoint biological mechanisms that could underly the discrepancy4,5. We showed that atrial fibrillation attenuates the protective effect of higher genetically predicted RHR on developing cardio-embolic stroke. This indicates either biological or mediated pleiotropic effects of atrial fibrillation in the association between genetically determined RHR and cardio-embolic stroke, which cannot be distinguished based on the current results. The relationship between a low RHR and cardioembolic stroke was attenuated by only 18.4% when corrected for atrial fibrillation, which might underestimated due to atrial fibrillation being a commonly missed diagnosis. Correction for atrial fibrillation only minimally affected the association between RHR and any or ischemic stroke, despite cardio-embolic stroke accounting for a substantial amount of ischemic stroke cases50. Although hypertension is another important risk factor for stroke, it commonly occurs in tandem with a higher and not a lower RHR4,51,52 and we found that neither systolic nor diastolic blood pressure affects the association between RHR and stroke. We did find that pulse pressure attenuates the association between RHR and any, ischemic and large-artery stroke. Lower RHR has previously been demonstrated to increase pulse pressure due to a higher likelihood of pressure wave reflections during prolonged systole53 and increased pulse pressure has been established as a risk factor of stroke53,54,55. Moreover, the Conduit Artery Functional Endpoint Study (CAFE) study postulated that pulse pressure underlies the inferiority of β-blocker based treatment (which lowers RHR) to amlodipine-based treatment in the prevention of stroke, despite equal effects on peripheral blood pressure53,56. Our results could be considered as support for this mechanism in the scenario that the RHR-associated genetic variants only affect pulse pressure through RHR and the association with stroke is primarily driven by RHR. However, MR-Steiger sensitivity analysis indicated that the association between the RHR-associated genetic variants and pulse pressure is unlikely mediated through RHR entirely. Biological pleiotropic effects are therefore more likely to cause the attenuation of the association between RHR and stroke when correcting for pulse pressure.
Finally, our study provides evidence that higher genetically predicted RHR increases the risk of developing dilated cardiomyopathy. The importance of decreasing RHR in the treatment of heart failure with reduced ejection fraction, the clinical phenotype of dilated cardiomyopathy, has been thoroughly studied. Beta-blockers have been shown to reduce mortality in individuals with heart failure with reduced ejection fraction and form the cornerstone of pharmacological treatment57,58,59. There is also evidence that ivabradine lowers cardiovascular mortality in heart failure with a reduced ejection fraction60. This protective effect is more likely due to its effect on RHR than heart rate variability as it has a larger effect on RHR61. The fact that the MR results were robust to the exclusion of SNPs associated with the −18 ms point of the R-peak, an established biomarker of dilated cardiomyopathy, supports the interpretation that current findings are driven by RHR differences that mimic pharmacological rate control14. Our MR on the compound definition of heart failure could be hampered by its phenotypical heterogeneity, as we were unable to differentiate between heart failure with reduced and preserved ejection fraction. It would be interesting to repeat the current MR analyses if more in-depth phenotyping on left ventricular ejection fraction and function becomes available, especially considering the different effects of RHR on familial dilated versus hypertrophic cardiomyopathy in the current study.
Several limitations should be considered. Although the current 493 RHR-associated genetic variants explained more than double the RHR variance compared to the 64 loci from our previous study7, there is still a large gap with heritability estimates from twin studies that range between 23% and 70%62,63,64. Future studies could include whole exome sequencing data to further increase our insights into the genetic architecture of RHR65. Second, individuals with cardiovascular diseases were included in the GWAS, which could potentially affect exposure-outcome associations. However, post-hoc analysis showed that UK Biobank participants with a history of cardiovascular disease or who used RHR-altering medication can be jointly analyzed with participants without such a medical profile. In addition, a two-sample MR strategy was adopted, reducing the risk that potential weak-instrument bias increases type 1 error rates through the reintroduction of confounding, population stratification, or correlated pleiotropy38. We note the broad biological nature of RHR genetic variants as illustrated by the diverse ECG patterns the genetic variants elicit on the full cardiac cycle. These broad effects should be taken into consideration for the correct interpretation of the MR results, as pleiotropy and reversed causation might be introduced in the MR. For example, some genetic variants were included in the MR analyses which could be more specific for another trait (i.e. rs2234962 near BAG3 for dilated cardiomyopathy). We believe that the influence of reversed causation on current results is minimal because we excluded variants more strongly associated with the outcome. The MR results were generally consistent across a multitude of sensitivity analyses, strengthening the interpretation of a true relationship. However, our study is not interventional in design, and a conservative interpretation of the results as generally unconfounded rather than causal estimates should be preferred. We stress that any causal claims can only be made if interventions or drugs alter RHR equal to the biological mechanisms in which RHR-associated genetic variants affect RHR.
In conclusion, our GWAS meta-analysis identified 493 RHR-associated genetic variants within 352 loci, to which we prioritized 670 candidate causal genes. We demonstrated cardiovascular tissues as the primary enrichment sites for RHR gene effects and showed that their gene expression is highest in cardiomyocytes. ECG signatures showed that RHR-associated genetic variants exert the largest effect on RHR through ventricular repolarization. We found no evidence for linear and non-linear associations between genetically predicted RHR and all-cause mortality across several analyses, suggesting that the well-known link between higher RHR and all-cause mortality reflects confounding factors and reversed causation. The results point towards an inverse association between genetically predicted RHR and the development of atrial fibrillation and any stroke, ischemic stroke, and cardio-embolic stroke, whereas it is positively associated with dilated cardiomyopathy development. Multivariable MR analyses showed that atrial fibrillation attenuates the protective effect of higher RHR on the development of cardio-embolic stroke. Pulse pressure attenuates the protective effects on any stroke, ischemic and large artery stroke, but this likely reflects biological pleiotropy rather than true mediation.
Methods
Method details
Populations
The full RHR meta-analysis included 100 studies with data on RHR in up to 835,465 individuals. RHR was obtained from ECG in 54 studies, from pulse rate in 31 studies (of which seven were self-measured by the participants), from blood pressure monitor in nine studies, from electronic medical records in three studies, from manual measurement in one study and through a combination of multiple of the before mentioned methods in two studies. Further information on cohort characteristics is provided in Supplementary Data 1 and statistical details are provided in the “Genome-wide association studies” section.
Imputation and quality control
Genotyping and quality control before imputation were performed using different genome-wide genotyping arrays and methods, as further detailed in Supplementary Data 1.
The UK Biobank was imputed to the Haplotype Reference v1.1 panel (HRC) by the Wellcome Trust Centre for Human Genetics. Analysis has been restricted to variants that are in the HRC v1.1. Quality control of samples and variants and imputation was performed by the Wellcome Trust Centre for Human Genetics, as described in more detail elsewhere66.
The 99 cohorts of the IC-RHR were imputed to 1000 Genomes Phase 1 and 3. For further information, please see Supplementary Data 1.
On the cohort level, we performed quality control by (1) re-formatting and SNP-name harmonization; (2) checking the used reference panel by plotting effect allele frequency plots using 1000G as a reference; (3) checking for genomic inflation by plotting QQ plots; (4) checking the betas by plotting histograms of the beta, frequency and info; (5) comparison of the expected P-value based on beta and standard error versus reported P-values.
Association with other traits
Genetic correlation analyses with GWAS of previously investigated traits were performed using LD Hub platform67. Genetic correlations were considered significant if they achieved a Bonferroni-corrected significance threshold of P < 0 .05/855 = 5.85 × 10−5. The GWAS Catalog was queried to find previously established genetic variants (P < 1 × 10−5) in LD (R2 > 0.8) with all 493 RHR variants68. Summary statistics were downloaded from the NHGRI-EBI GWAS Catalog on 27/04/2020.
Functional annotation of genes
For all independent genetic variants that were genome-wide significantly associated in the final meta-analysis, candidate causal genes were prioritized as followed: (1) by proximity, the nearest gene and any other gene within 10 kb; (2) protein-coding genes containing variants in LD with RHR-associated variants at R2 > 0.8; (3) eQTL genes in LD with RHR-associated variants at R2 > 0.8; and (4) DEPICT gene mapping using variants that achieved P < 1 × 10−8 (further information described below). Annotation of all identified genes was performed by querying GeneALacart69.
Query of dbNSFP
The dbNSFP database (version 3a) was queried to obtain functional prediction and annotation of all potential non-synonymous genetic variants70. The dbNSFP database contains information on multiple prediction algorithms and conservation scores further detailed elsewhere70.
eQTL analyses
Colocalization of multiple expression quantitative trait loci (eQTL) was performed using SMR and HEIDI analyses (version 0.710)13 in data repositories from GTEx V771, GTEx brain71, Brain-eMeta eQTL72, and blood eQTL from Westra73 and CAGE74. Colocalization analyses were performed to test whether the effect size of the RHR-associated variants on the phenotype is most likely mediated by gene expression13. eQTL genes were considered as candidate causal genes if they achieved a significance after Bonferroni correction for the amount of eQTLs tested (P < 0.05/188,737 = 2.65 × 10−7), passed the HEIDI test at P > 0.05, and if the lead variants of the eQTL genes were in LD (R2 > 0.8) with the RHR-associated genetic variants.
DEPICT analyses
DEPICT was used to find genes associated with identified variants, enriched gene sets, and tissues in which these genes are highly expressed. DEPICT.v1.beta version rel137 (obtained from https://data.broadinstitute.org/mpg/depict/) was used to perform integrated gene function analyses as stated above36. DEPICT was run using all genetic variants that achieved P < 1 × 10−8. Genes were considered possible candite genes if FDR < 0.05, taking into account multiple hypothesis testing.
Pathway analyses
DEPICT was used to find enriched gene sets using the settings described above36. Enriched genesets were further clustered on the basis of the correlation between scores for all genes using an Affinity Propagation method as provided by DEPICT36. Each cluster was named according to the name of the most central gene set as identified using the Affinity Propagation method. Identified meta-clusters were compared to the clusters found in the study of Eppinga et al. and were determined to be new if not a single cluster within the meta-cluster had been identified before. Clustering was performed using DEPICT software in python 2.775 and visualization using Cytoscape 3.8.076.
Tissue enrichment
DEPICT was used to find enriched tissues using the settings described above36. Enriched tissues were further investigated by performing conditional analyses to provide evidence for an independent association with RHR. The following formula was used:
Here, Zt is the maximum Z-value of all tissue Z-values, Zs a vector of all tissue Z-values, and ρts the correlation between the tissue of Zt and the tissue of Zs77. The maximum Z-value (Zt) was determined for every new iteration. Conditional analyses were performed up until the highest Z-value reached 2.585, which corresponds to the lowest Z-value with an FDR < 0.05.
ECG morphology
The ECGenetics browser was used to gain insights into the electrophysiological effect of the RHR-associated genetic variants14. Detailed information on the methodology can be found in the study of Verweij et al. and is briefly discussed below. The ECGenitics browser contains genome-wide summary statistics of the complete cardiac cycle. The complete cardiac cycle was defined using two methods, including (a) the signal-averaged electrocardiographic beat surrounding the R wave at a resolution of 500 Hz resulting in 500 averaged data points and (b) R–R intervals corrected signal (made of equal length of 500 data points).
All RHR-associated genetic variants were tested for their association with both the non-normalized and normalized association patterns. A heatmap was constructed containing all associated genetic variants associated with at least one point on the ECG at a Bonferonni-corrected P-value of 0.05/493/(500 × 2) = 1 × 10−7. Effects were aligned to the most positively associated allele across all time points. The heatmap shows a hue ranging from red (positive effect) to a blue color (negative effect) color scale, with yellow indicating no effect. Secondly, the total effect of the 493 RHR-associated genetic variants on ECG morphology was assessed using an ECG-wide MR approach (inverse variance weighted fixed-effects model) on the non-normalized and normalized association pattern.
Single-nucleus RNA expression
All genes prioritized in the current study were queried in the single-cell data from the study of Tucker et al. through the Broad Institute’s Single Cell Portal (available at: https://singlecell.broadinstitute.org/single_cell/study/SCP498/transcriptional-and-cellular-diversity-of-the-human-heart under study ID SCP49) to gain insights in their transcriptional and cellular diversity15. We selected the 86 genetic variants strongly associated with at least one ECG time point. We took forward the most likely candidate gene per genetic variant, based on the amount of gene identification strategies by which the gene was identified. When a genetic variant highlighted multiple genes identified by the same amount of gene identification strategies, we took forward the gene with the highest biological plausibility of involvement in RHR biology. A dotted heatmap was constructed for this subset of genes.
UK Biobank definitions
In the UK Biobank, we captured the prevalence and incidence of functional outcomes through data collected at the Assessment Centre in-patient Health Episode Statistics (HES) and data on the cause of death from the National Health Service (NHS) Information Centre. Prevalence of disease was also based on an interview with a trained nurse at the baseline visit (self-reported). HES data were available up to 31-03-2017 for English participants, 29-02-2016 for Welsh participants, and 31-10-2016 for Scottish. Information on cause of death was available for participants from England and Wales until 31-01-2018, and from the NHS Central Register Scotland for participants from Scotland until 30-11-2016. Definitions of all-cause mortality, 35 leading causes of mortality (defined as any cause of mortality with a prevalence >0.1%), coronary artery disease, myocardial infarction, atrial fibrillation, stroke (any stroke, any ischemic stroke), heart failure and subtypes (hypertrophic cardiomyopathy, dilated cardiomyopathy) are provided in Supplementary Data 15. Longevity was obtained through questionnaires in which participants were asked to provide the age of death of both parents. Individuals were excluded in case the answer was older than 115 years, if they reported themselves as adopted, if their parent was still alive but not yet long-lived, or if their parent died prematurely (fathers <46 years or mothers <57 years), in line with previously established methods37. Combined parental longevity was assessed by summing Z-scores of the age of death from both parents if the information on both parents was provided37. Systolic and diastolic blood pressure values were obtained through two automated and/or two manual blood pressure measurements. The average value of all available blood pressure measurements was used per phenotype. Automated measurements were corrected according to the previously described methodology78. In addition, we corrected systolic and diastolic blood pressure for medication use, by adding respectively 15 and 10 mmHg to the blood pressure trait79. Pulse pressure was calculated by subtracting diastolic from systolic blood pressure.
Statistical details of the analyses on functional outcomes are provided in the “Genetics and regression analyses on functional outcomes in the UK Biobank” and “Mendelian randomization” sections.
External cohort definitions
External cohorts included the CARDIoGRAMplusC4D80, AFGen81, MEGASTROKE50, and ICBP-plus19 consortia and descriptions have been detailed previously. Effect sizes from the ICBP-plus consortium were obtained from the meta-analysis of the UK Biobank and ICBP-plus, after subtracting the effects from the UK Biobank (for further details, see the section “Meta-subtract of blood pressure traits”). An overview of these studies is provided in Supplementary Data 16. We searched for proxies (LD > 0.8) in case variants could not be found within the outcome datasets.
Quantification and statistical analysis
Genome-wide association studies
All included cohorts performed genetic variant association analyses on RHR using linear regression analyses assuming an additive genetic model (Supplementary Data 1). No transformation of heart rate was performed and extreme (>4 SD) phenotypic outliers were excluded analogous to previous GWAS on RHR and as per predefined criteria7. The GWAS model was adjusted for age, age2, body mass index, sex, and study-specific covariates (e.g. principal components, genotyping array, and RHR measuring method in case multiple RHR methods were used within a study).
The UK Biobank GWAS was performed using BOLT-LMM v2.3beta2, employing a mixed linear model that corrects for population structure and cryptic relatedness82. A total of 484,307 participants from the UK Biobank remained available for the GWAS after the exclusion of 14,242 individuals for whom no genetic data was available, 1341 individuals who failed genetic quality control, 1058 individuals who were outside the 4SD range for RHR, and 1587 individuals due to missing covariates (Supplementary Data 1).
Study-specific details and methodology of the 99 cohorts of the IC-RHR are provided in Supplementary Data 1. Several software programs were used for the analysis, including mach2qtl83, minimac84, minimac285, IMPUTE286, GEEPACK87, ProbaABEL88, and MMAP89, for which version details per cohort are provided in Supplementary Data 1. A fixed effect meta-analysis using the inverse variance method in METAL was performed on all 99 cohorts, including up to a total of 351,158 individuals90. Genomic control was applied at the study level by correcting for the study-specific lambda.
All genetic variants were excluded if they had poor imputation quality score (Info < 0.3) and effective sample size (Neff) < 25 for the genetic variants computed as sample size × Info × 2 × minor allele frequency (MAF)×(1−MAF). After these exclusions, a total of 19,400,415 and 27,082,649 variants remained available for the UK Biobank and IC-RHR GWAS respectively.
Again, a fixed-effects meta-analysis using the inverse variance method in METAL was performed to pool the data from the UK Biobank and IC-RHR up to 835,465 participants using ~30M genetic variants90. LD score regression software (v1.0.0) was used to calculate linkage disequilibrium score regression intercepts and attenuation ratios11,12. We corrected for genomic inflation prior to the meta-analysis by multiplying the standard errors with the square root of linkage disequilibrium score regression intercepts in the UK Biobank (1.132 ± 0.017) and the IC-RHR (1.020 ± 0.010)11,12.
PLINK (version 1.9) was used to prune genetic variants in a set of independently associated variants91. An independent genetic variant was defined as a genome-wide significant genetic variant in low LD (R2 < 0.005) with another genome-wide significant variant within a five-megabase window. A genetic locus was defined as the most significant variant in a megabase region at either side of the independent genetic variant.
A single one-stage replication analysis was performed next. The following criteria had to be satisfied for a signal to be reported as a replicated signal for RHR:
-
1.
the sentinel genetic variant has P < 1 × 10−8 in the discovery (UKB + IC-RHR) meta-analysis;
-
2.
the sentinel genetic variant shows support (P < 0.01) in the UKB GWAS alone;
-
3.
the sentinel genetic variant shows support (P < 0.01) in the IC-RHR meta-analysis alone;
-
4.
the sentinel genetic variant has the concordant direction of effect between UKB and IC-RHR datasets;
The sentinel genetic variants were compared with previous loci from previous GWAS of RHR and were determined novel if located outside a 1-megabyte distance of previously RHR-associated loci7,8,10. We selected the P-value thresholds to be an order of magnitude more stringent than a genome-wide significance P-value to ensure robust results and to minimize false positive findings.
Post-hoc quality control
We performed additional analyses to investigate whether individuals with a history of cardiovascular disease or those who took RHR-altering medication could influence the results of the GWAS. The UK Biobank population was stratified by a medical history of any cardiovascular disease or reported intake of RHR-altering medication. A history of any cardiovascular disease was defined according to the definition in Supplementary Data 15. RHR altering medication was defined as intake of beta-blockers, calcium antagonists, sotalol, amiodarone, flecainide, anti-depressants, atropine, other anti-cholinergic medication, cardiac glycosides, diuretics, ACE-inhibitors or angiotensin II receptor blockers, analogous to previous methods92. Linear regressions on RHR were performed in both populations, using cluster-robust standard errors with genetic family IDs as clusters to account for the relatedness among participants. Exclusions and covariates were similar to those used for the GWAS. Individuals belonging together based on 3rd-degree or closer as indicated by the kinship matrix (kinship coefficient > 0.0442) provided by UK Biobank received a family ID. A Chow test was used to investigate whether there were significant differences in beta estimates in participants with and without cardiovascular disease or RHR-altering medication93. The post-hoc quality control was performed using the statistical software STATA 15 (StataCorp LP).
Genetics and regression analyses
All of the outcomes assessed in the UK Biobank that are reported in this manuscript have been adjusted for age, sex, the first 30 principal components (PCs) to account for population stratification, and genotyping array (Affymetrix UK Biobank Axiom® array or Affymetrix UK BiLEVE Axiom array). The exclusions were performed according to the above-mentioned methods for the GWAS of RHR in the UK Biobank. In addition, we excluded 74,471 individuals based on familial relatedness, after which 412,481 individuals remained available for further analyses.
SNP-outcome associations for all outcomes (see the section “UK Biobank definitions”) were obtained for all 493 variants with a P < 1 × 10−8 in the RHR GWAS (see section “Mendelian randomization analyses”). The associations with all-cause mortality and 35 leading causes of mortality within the UK Biobank (defined as a prevalence higher than 0.1%) were obtained using a Cox proportional hazard model during a median (interquartile range) follow-up of 8.9 (8.2–9.5) years. The associations with parental longevity was assessed using linear regression analyses. The associations with both prevalent and incidence of cardiovascular diseases were assessed using logistic regression analyses. Cox and linear regressions were corrected for age at baseline, while the logistic regression analysis was corrected for age until the last date of follow-up to correctly account for both prevalent and incident disease.
We performed an in-depth assessment of the association between RHR and all-cause mortality in the UK Biobank by systematically altering the differences between the current study and the previous study from Eppinga et al., which included (a) the set of SNPs, (b) the P-value threshold for SNP inclusion, (c) the assessment of the outcome in an independent cohort, and (d) the follow-up length7. Genetic risk scores for RHR were created following an additive model by summing the number of alleles (0, 1, or 2) for each individual after multiplication with the effect size for RHR. Genetic risk scores were constructed using the 493 discovered variants within the full meta-analyses using the effect sizes of the IC-RHR, the effect sizes of the UK Biobank, and using the 73 previously discovered variants at five P-value thresholds (1 × 10−8, 5 × 10−8, 1 × 10−7, 1 × 10−6, 1 × 10−5). These were transformed to translate to a change of 5 bpm. The association with all-cause mortality was tested using Cox regression analyses in different populations of the UK Biobank. One population included all individuals (ncases = 16,289, ncontrols = 396,183). Another population included a subset of individuals which were genotyped for the UK Biobank interim release from May 2015, which included in the GWAS by Eppinga et al. (ncases = 4953, ncontrols = 133,102). The final population consisted of a subset of individuals without genetic information at the time of the UK Biobank interim release, which was therefore not included in the GWAS by Eppinga et al., ncases = 11,336, ncontrols = 283,081). Please note that sample sizes might slightly differ from those in the previous GWAS due to updated exclusions. Lastly, point d) was taken into account by re-performing above-mentioned steps using mortality data up until the previously available follow-up (All individuals, ncases = 7099, ncontrols =405,373; individuals not included in the GWAS by Eppinga et al., ncases = 5000, ncontrols = 289,417; and those included in the GWAS by Eppinga et al., ncases = 2099, ncontrols = 115,956). All regression analyses were performed using the statistical software STATA 15 (StataCorp LP).
Mendelian randomization analyses
All 493 independent genetic variants at P < 1 × 10−8 in the final meta-analysis were taken forward in the MR. To minimize overlap between exposure and outcome cohorts, effect sizes were taken from the IC-RHR data to test the associations with outcomes within the UK Biobank, whereas effect sizes were taken from the UK Biobank to test the association within other independent cohorts. Proxies (LD > 0.8) were searched in case genetic variants could not be found within the UK Biobank or IC-RHR. All effect sizes were transformed to translate to a change in RHR of 5 bpm.
Potential weak instrument bias was assessed by calculating the F-statistic using the following equation:
In this formula, n is the sample size of the exposure and R2 is the amount of variance of the exposure explained by the SNP94. R2 was calculated based on summary statistics using a previously established formula95. Genetic variants were not excluded from further analyses if the F-statistic was <10 as this can exacerbate bias by increasing the chance of winner’s curse38. Exposure and outcome summary statistics were then harmonized using the TwoSample MR package96. Forward strand alleles were inferred using allele frequency information and palindromic SNPs were removed if the MAF was above the recommended setting of 0.4296. MR-Steiger filtering was applied to explore pleiotropic effects through the assessment of potential reversed causation. R2 for both the exposure and outcome were calculated and variants were removed from further analyses if the R2 of the exposure is significantly lower (P-value < 0.05) than the R2 of the tested outcome97. R2 for linear traits was calculated as described above95, R2 for binary outcomes was calculated on the liability scale98. A true causal direction was assumed if the R2 for binary outcomes was too small to be correctly estimated. Variants were excluded from further analyses in case a false causal direction was indicated.
The linear association between genetically determined RHR on all outcomes was initially assessed using the IVW multiplicative random-effects method, which provides a consistent estimate under the assumption of balanced pleiotropy. The Rücker framework was applied to assess heterogeneity and thus potential pleiotropy within the MR effect estimates99. A Cochran’s Q P-value of <0.05 was considered as proof of heterogeneity within the IVW estimate and, as a consequence, balanced horizontal pleiotropy. An I2 index >25% supports this conclusion100. The MR-Egger test was performed to allow SNPs to exert unbalanced horizontal pleiotropy101. The Rücker framework assesses heterogeneity within the MR-Egger regression (Rucker’s Q) and calculates the difference between heterogeneity within the IVW effect estimate (Q–Q’)99. A significant Q–Q’ (P < 0.05) in combination with a significant non-zero intercept of the MR-Egger regression (P < 0.05) was considered an indication of unbalanced horizontal pleiotropy. We then moved from an IVW model to the MR-Egger model as initial analysis, as the MR-Egger can provide causal estimates if SNPs exert unbalanced horizontal pleiotropy under the assumption that the Instrument Strength Independent of Direct Effect (InSIDE) assumption holds. Weak instrument bias in the MR-Egger regression analysis was assessed by I2GX and was considered to indicate a low risk of measurement error if larger than 95%102. The MR-Lasso method was used to find consistent estimates under the same assumptions as the IVW method, but only for the set of genetic variants not identified as outlier103. This method is most valuable in the scenario that a small proportion of the genetic variants is invalid and shows heterogeneous ratio estimates103. The weighed median approach was used to provide a consistent estimate if up to half of the variants are invalid. Finally, we performed the MR contamination mixture method to provide a consistent estimate if no larger subset of invalid genetic variants estimates the same causal association than the subset of valid genetic variants104.
The non-linear associations of genetically predicted RHR with all-cause mortality and cardiovascular diseases were assessed using a fractional polynomial method105,106. These associations were assessed using the UK Biobank as an outcome cohort, considering this was the largest cohort with individual-level data available to us. Consequently, we used the independent weights of the IC-RHR meta-analysis to construct a weighted polygenetic risk score of RHR by summing the number of alleles (0, 1, or 2) for each individual after multiplication with the effect size between the genetic variant and RHR. We first calculate residual RHR by subtracting the results of the regression of RHR from the polygenetic score of RHR from RHR itself. Covariates of the regression included age, age2, sex, BMI, genotyping array, and PC1-PC30, analogous to the GWAS. Residual RHR, which characterizes the predicted RHR for an individual if their polygenetic score took the value zero, was then divided into 30 quantiles. Stratifying on residual RHR rather than total RHR avoids overadjustment and collider bias as residual RHR is not downstream of the effect of the genetic variants on the outcome in a causal diagram. We then calculated the genetic associations with the exposure in each stratum of residual RHR using linear regression analyses, correcting for the same covariates as described above. Two tests for non-linearity in the genetic association with the exposure (trend and Cochran’s Q tests) were performed to investigate heterogeneity in the polygenetic score of RHR on residual RHR in different strata. We then calculated the genetic associations with the outcome in each stratum. The same methodology was used as described in the section “Genetics and regression analyses”, including the same covariate model (age, sex, genotyping array, and PC1-PC30) and regression type (Cox regression for all-cause mortality and logistic regression for cardiovascular diseases). The outcome regression coefficient was then divided by the exposure regression coefficient as a ratio of coefficients to obtain local average causal effects (LACE) in each stratum. These localized average causal effects were meta-regressed against the mean of the exposure in each stratum in a flexible semiparametric framework, using the derivative of fractional polynomial models of degrees 1 and 2. All possible fractional polynomials of degrees 1 and 2 were fitted using the powers −2, −1, 0, 0.5, 1, 2, and 3106. The fractional polynomial of degree 1 is fit to the data if the fractional polynomial of degree 1 was as good of a fit (P > 0.05) as the degree 2 as indicated by the likelihood ratio test. Three tests for non-linearity of the association between genetically predicted RHR and the outcomes are reported: a trend test, which assesses for a linear trend among the localized average causal effect estimates, a Cochran’s Q test, and a fractional polynomial test, which assesses whether a non-linear model fits the localized average causal effect estimates better than a linear model. Please note that before fitting the fractional polynomials, we subtracted 45 from the values of RHR as the most flexible fit is achieved when the exposure is close to 0 but still positive. A reference of RHR of 70 bpm was taken as this was close to the mean RHR of 69.3 bpm. An additional 1390 individuals were dropped compared to the linear MR estimates obtained from the UK Biobank cohort due to missing BMI values necessary for the correction of the exposure regression coefficients.
A multivariable MR approach was used to gain additional insights into the relationship between RHR (effect sizes of the UK Biobank) and (subtypes of) stroke from the MEGASTROKE consortium. We used either atrial fibrillation (AFgen consortium81), systolic blood pressure, diastolic blood pressure, or pulse pressure (ICBP consortium, please see the section “Meta-substract of blood pressure traits” for further details19) as secondary exposures to obtain insights in the direct effect of RHR on (subtypes of) stroke that are independent of this secondary exposures107. First, a multivariable MR-IVW method was used, in which for each exposure the instruments are selected and regressed together against the outcome, weighting for the inverse variance of the outcome107. Weak instrument bias for any of the exposures was assessed using Qx1 and Qx2107. When both are larger than the critical value on the χ2 distribution, there is little evidence of weak instrument bias. The critical value on the χ2 distribution was calculated by subtracting one degree of freedom from the amount of SNPs at a P-value of 0.05. Qa was considered to indicate potential pleiotropy when larger than the critical value on the χ2 distribution as calculated by the amount of SNPs minus two degrees of freedom at a P-value of 0.05107. Multivariable MR-Egger was performed to allow for unbalanced horizontal pleiotropy108. An MR-Egger intercept with a P-value < 0.05 in combination with a significant Qa was considered proof of unbalanced horizontal pleiotropy, and consequently the MR-Egger regression to provide a robust causal estimate108. Multivariable MR-Lasso analysis was performed as this method provides consistent estimates even when half of the genetic variants are invalid instruments and display unbalanced pleiotropy109. We also performed multivariable weighted median analysis as this type of analysis has been shown to perform well under higher levels of pleiotropy109. We did not search for proxies in the multivariable MR setting as this could introduce uncertainty through different LD patterns between the secondary exposure and outcome and we therefore re-estimate the univariable effect of RHR on the outcome with the eligible SNPs to allow for a better comparison of the results.
We assessed whether the Wald estimates between the RHR-associated genetic variants and the cardiovascular disease outcomes could identify risk loci not previously associated with these outcomes in their respective GWASs. The genetic variants were considered associated with the outcome if (a) the Wald estimates had concordant effects within the UK Biobank as well as either the CARDIoGRAMplusC4D80, AFGen81, or MEGASTROKE50 cohorts, (b) when the Wald estimates were significant at a Bonferonni corrected threshold of P < 1.01 × 10−4, that is, α = 0.05 with Bonferroni correction for a maximum of 493 independent tests, and (c) the genetic variant did not reach a genome-wide significant threshold of P-value < 5 × 10−8 in either one of the outcome cohorts used in the current study.
MR analyses were performed using R (version 3.6.3), the TwoSampleMR package (version 0.5.3)96, and the MR-Lasso source code103. The multivariable MR analyses were performed using the MVMR (version 0.3)107 and MendelianRandomization (version 0.5.1) packages110. Non-linear MR analyses were performed based on previously described methods105. For the MR on (subtypes of) mortality, we considered a liberal two-sided P-value of P < 0.05 significant for any of the outcomes using the IVW-MR random effects model. For the MR on cardiovascular diseases, we considered a Bonferroni corrected two-sided P-value for the amount of unique outcomes (P = 0.05/12 = 4.17 × 10−3) to be significant for the main IVW-MR random effects analyses, and a two-sided P-value between 4.17 × 10−3 and 0.05 to indicate suggestive evidence for an association. A two-sided P-value threshold of P < 0.05 was adopted for the sensitivity analyses.
Meta-subtract of blood pressure traits
We used the MetaSubtract (version 1.60) package in R to remove the effects sizes of the UK Biobank from the largest blood pressure GWAS’s to date in order to obtain the independent effect sizes of the ICBP consortium19,111. Effect sizes for the UK Biobank were obtained through linear regression analyses using every RHR SNP available in the UK Biobank as exposure, and systolic, diastolic, and pulse pressure as outcomes. Covariates included age, age2, sex, BMI, genchip, and PC1-PC30. Cluster-robust standard errors with genetic family IDs as clusters were used to account for the relatedness among participants. Individuals belonging together based on 3rd-degree or closer as indicated by the kinship matrix (kinship coefficient > 0.0442) provided by UK Biobank received a family ID. To keep the cohort similar to the one used in the study from Evangelou et al., we excluded those who self-reported as of non-European ancestry (n = 18,405) and pregnant women (n = 306) from the 484,307 included in the GWAS, leaving 465,659 individuals for the analysis19. We note that we did not correct the standard errors for the genomic inflation reported for the GWASs of blood pressure traits in the UK Biobank as our linear regression estimates, while resembling the GWAS data, will not be exactly equal to BOLT-LMM estimates due to different methodologies82.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
All data supporting the findings described in this manuscript are available in the article and its Supplementary Information files. The genome-wide summary statistics, excluding the 23andMe data, generated in this study have been deposited in a Mendeley database available through https://data.mendeley.com/datasets/9b725x7mvb/draft?a=f8619d91-5c4d-4e4f-8f44-a73692a332a5. The top 10,000 genetic variants, including the 23 and Me data, can be downloaded from the same repository. The full GWAS summary statistics, including 23andMe data, will be made available through 23andMe to qualified researchers under an agreement with 23andMe that protects the privacy of the 23andMe participants. Datasets will be made available at no cost for academic use. Please visit https://research.23andme.com/collaborate/#dataset-access/ for more information and to apply to access the data. The estimated average review time is 3 months. Once this has been approved, applicants can send the confirmation to the lead author of the manuscript to receive the full summary statistics. The raw data of all cohorts are protected and are not available due to data privacy laws. Referenced datasets can be obtained through their respective publications cited in the manuscript, or otherwise be accessed by the URLs provided below. Referenced data includes databases from dbNSFP (https://sites.google.com/site/jpopgen/dbNSFP), public eQTL repositories (https://cnsgenomics.com/software/smr/#DataResource), GWAS catalog (https://www.ebi.ac.uk/gwas/home), GeneALacart (https://genealacart.genecards.org/), LD hub (http://ldsc.broadinstitute.org/), ECGenetics (http://www.ecgenetics.org), single nucleus RNA expression (https://singlecell.broadinstitute.org/single_cell/study/SCP498/transcriptional-and-cellular-diversity-of-the-human-heart#study-summary). Publicly available GWAS summary statistics were used for the Mendelian randomization analyses, further information and URLs are detailed in Supplementary Data 16.
Code availability
The analysis in the current manuscript was performed using previously published software and code. Further information on scripts and coding required to reproduce this work is available from the Lead Contact upon request.
References
-
Jouven, X. et al. Heart-rate profile during exercise as a predictor of sudden death. N. Engl. J. Med. 352, 1951–1958 (2005).
Google Scholar
-
Zhang, D., Wang, W. & Li, F. Association between resting heart rate and coronary artery disease, stroke, sudden death and noncardiovascular diseases: a meta-analysis. Can. Med. Assoc. J. 188, E384–E392 (2016).
Google Scholar
-
Münzel, T. et al. Heart rate, mortality, and the relation with clinical and subclinical cardiovascular diseases: results from the Gutenberg Health Study. Clin. Res. Cardiol. 108, 1313–1323 (2019).
Google Scholar
-
O’Neal, W. T. et al. Heart rate and ischemic stroke: the reasons for geographic and racial differences in stroke (REGARDS) study. Int. J. Stroke 10, 1229–1235 (2015).
Google Scholar
-
Lonn, E. M. et al. Heart rate is associated with increased risk of major cardiovascular events, cardiovascular and all-cause death in patients with stable chronic cardiovascular disease: an analysis of ONTARGET/TRANSCEND. Clin. Res. Cardiol. 103, 149–159 (2014).
Google Scholar
-
Smith, G. D. & Ebrahim, S. ‘Mendelian randomization’: can genetic epidemiology contribute to understanding environmental determinants of disease? Int. J. Epidemiol. 32, 1–22 (2003).
Google Scholar
-
Eppinga, R. N. et al. Identification of genomic loci associated with resting heart rate and shared genetic predictors with all-cause mortality. Nat. Genet. 48, 1557–1563 (2016).
Google Scholar
-
Den Hoed, M. et al. Identification of heart rate-associated loci and their effects on cardiac conduction and rhythm disorders. Nat. Genet. 45, 621–631 (2013).
Google Scholar
-
Larsson, S. C., Drca, N., Mason, A. M. & Burgess, S. Resting heart rate and cardiovascular disease. Circ. Genom. Precis. Med. 12, e002459 (2019).
Google Scholar
-
Guo, Y. et al. Genome-wide assessment for resting heart rate and shared genetics with cardiometabolic traits and Type 2 diabetes. J. Am. Coll. Cardiol. 74, 2162–2174 (2019).
Google Scholar
-
Bulik-Sullivan, B. K. et al. LD Score regression distinguishes confounding from polygenicity in genome-wide association studies. Nat. Genet. 47, 291–295 (2015).
Google Scholar
-
Loh, P.-R., Kichaev, G., Gazal, S., Schoech, A. P. & Price, A. L. Mixed-model association for biobank-scale datasets. Nat. Genet. 50, 906–908 (2018).
Google Scholar
-
Wu, Y. et al. Integrative analysis of omics summary data reveals putative mechanisms underlying complex traits. Nat. Commun. 9, 918 (2018).
Google Scholar
-
Verweij, N. et al. The genetic makeup of the electrocardiogram. Cell Syst. 11, 229–238.e5 (2020).
Google Scholar
-
Tucker, N. R. et al. Transcriptional and cellular diversity of the human heart. Circulation 142, 466–482 (2020).
Google Scholar
-
Eijgelsheim, M. et al. Genome-wide association analysis identifies multiple loci related to resting heart rate. Hum. Mol. Genet. 19, 3885–3894 (2010).
Google Scholar
-
Nagy, R. et al. Exploration of haplotype research consortium imputation for genome-wide association studies in 20,032 Generation Scotland participants. Genome Med. 9, 1 (2017).
Google Scholar
-
Huet, G. et al. Actin-regulated feedback loop based on Phactr4, PP1 and cofilin maintains the actin monomer pool. J. Cell Sci. 126, 497–507 (2013).
Google Scholar
-
Evangelou, E. et al. Genetic analysis of over 1 million people identifies 535 new loci associated with blood pressure traits. Nat. Genet. 50, 1412–1425 (2018).
Google Scholar
-
Peshavaria, M. & Day, I. N. Molecular structure of the human muscle-specific enolase gene (ENO3). Biochem. J. 275, 427–433 (1991).
Google Scholar
-
Keller, A. et al. Differential expression of α- and β-enolase genes during rat heart development and hypertrophy. Am. J. Physiol.- Hear. Circ. Physiol. 269, 1843–1851 (1995).
Google Scholar
-
Cui, Y. et al. Single-cell transcriptome analysis maps the developmental track of the human heart. Cell Rep. 26, 1934–1950.e5 (2019).
Google Scholar
-
Reverter, D. & Lima, C. D. Structural basis for SENP2 protease interactions with SUMO precursors and conjugated substrates. Nat. Struct. Mol. Biol. 13, 1060–1068 (2006).
Google Scholar
-
Mendler, L., Braun, T. & Müller, S. The ubiquitin-Like SUMO System and heart function: from development to disease. Circ. Res. 118, 132–144 (2016).
Google Scholar
-
Kim, E. Y. et al. Enhanced desumoylation in murine hearts by overexpressed SENP2 leads to congenital heart defects and cardiac dysfunction. J. Mol. Cell. Cardiol. 52, 638–649 (2012).
Google Scholar
-
Kang, X. et al. SUMO-specific Protease 2 is essential for suppression of polycomb group protein-mediated gene silencing during embryonic development. Mol. Cell 38, 191–201 (2010).
Google Scholar
-
Hoffmann, T. J. et al. Genome-wide association analyses using electronic health records identify new loci influencing blood pressure variation. Nat. Genet. 49, 54–64 (2017).
Google Scholar
-
Mahajan, A. et al. Refining the accuracy of validated target identification through coding variant fine-mapping in type 2 diabetes. Nat. Genet. 50, 559–571 (2018).
Google Scholar
-
Prins, B. P. et al. Exome-chip meta-analysis identifies novel loci associated with cardiac conduction, including ADAMTS6. Genome Biol. 19, 87 (2018).
Google Scholar
-
van Setten, J. et al. PR interval genome-wide association meta-analysis identifies 50 loci associated with atrial and atrioventricular electrical activity. Nat. Commun. 9, 2904 (2018).
Google Scholar
-
Wuttke, M. et al. A catalog of genetic loci associated with kidney function from analyses of a million individuals. Nat. Genet. 51, 957–972 (2019).
Google Scholar
-
van der Harst, P. & Verweij, N. Identification of 64 novel genetic loci provides an expanded view on the genetic architecture of coronary artery disease. Circ. Res. 122, 433–443 (2018).
Google Scholar
-
Shadrina, A. S. et al. Prioritization of causal genes for coronary artery disease based on cumulative evidence from experimental and in silico studies. Sci. Rep. 10, 10486 (2020).
Google Scholar
-
Nielsen, J. B. et al. Biobank-driven genomic discovery yields new insight into atrial fibrillation biology. Nat. Genet. 50, 1234–1239 (2018).
Google Scholar
-
Roselli, C. et al. Multi-ethnic genome-wide association study for atrial fibrillation. Nat. Genet. 50, 1225–1233 (2018).
Google Scholar
-
Pers, T. H. et al. Biological interpretation of genome-wide association studies using predicted gene functions. Nat. Commun. 6, 5890 (2015).
Google Scholar
-
Pilling, L. C. et al. Human longevity is influenced by many genetic variants: Evidence from 75,000 UK Biobank participants. Aging (Albany, NY) 8, 547–560 (2016).
Google Scholar
-
Burgess, S. & Thompson, S. G. Avoiding bias from weak instruments in Mendelian randomization studies. Int. J. Epidemiol. 40, 755–764 (2011).
Google Scholar
-
Shigetoh, Y. et al. Higher heart rate may predispose to obesity and diabetes mellitus: 20-year prospective study in a general population. Am. J. Hypertens. 22, 151–155 (2009).
Google Scholar
-
Zhang, A. et al. Resting heart rate, physiological stress and disadvantage in Aboriginal and Torres Strait Islander Australians: analysis from a cross-sectional study. BMC Cardiovasc. Disord. 16, 36 (2016).
Google Scholar
-
Thelle, D. S. et al. Resting heart rate and physical activity as risk factors for lone atrial fibrillation: a prospective study of 309540 men and women. Heart 99, 1755–1760 (2013).
Google Scholar
-
Morseth, B. et al. Physical activity, resting heart rate, and atrial fibrillation: the Tromsø Study. Eur. Heart J. 37, 2307–2313 (2016).
Google Scholar
-
Elliott, A. D., Mahajan, R., Lau, D. H. & Sanders, P. Atrial fibrillation in endurance athletes: from mechanism to management. Cardiol. Clin. 34, 567–578 (2016).
Google Scholar
-
Liu, X. et al. Resting heart rate and the risk of atrial fibrillation a dose-response analysis of cohort studies. Int. Heart J. 60, 805–811 (2019).
Google Scholar
-
Siland, J. E. et al. Resting heart rate and incident atrial fibrillation: a stratified Mendelian randomization in the AFGen consortium. PLoS ONE 17, e0268768 (2022).
Google Scholar
-
Iwasaki, Y., Nishida, K., Kato, T. & Nattel, S. Atrial fibrillation pathophysiology. Circulation 124, 2264–2274 (2011).
Google Scholar
-
Kneller, J. et al. Cholinergic atrial fibrillation in a computer model of a two-dimensional sheet of canine atrial cells with realistic ionic properties. Circ. Res. 90, e73–e87 (2002).
Google Scholar
-
Lip, G. Y. H. et al. Hypertension and cardiac arrhythmias: a consensus document from the European Heart Rhythm Association (EHRA) and ESC Council on Hypertension, endorsed by the Heart Rhythm Society (HRS), Asia-Pacific Heart Rhythm Society (APHRS) and Sociedad Latinoamericana de Estimulación Cardíaca y Electrofisiología (SOLEACE). Europace 19, 891–911 (2017).
Google Scholar
-
Overvad, T. F. et al. Body mass index and adverse events in patients with incident atrial fibrillation. Am. J. Med. 126, 640.e9–17 (2013).
Google Scholar
-
Malik, R. et al. Multiancestry genome-wide association study of 520,000 subjects identifies 32 loci associated with stroke and stroke subtypes. Nat. Genet. 50, 524–537 (2018).
Google Scholar
-
Kannel, W. B., Kannel, C., Paffenbarger, R. S. & Cupples, L. A. Heart rate and cardiovascular mortality: the Framingham study. Am. Heart J. 113, 1489–1494 (1987).
Google Scholar
-
Grau, A. J. et al. Risk factors, outcome, and treatment in subtypes of ischemic stroke: the German stroke data bank. Stroke 32, 2559–2566 (2001).
Google Scholar
-
Williams, B. et al. Differential impact of blood pressure-lowering drugs on central aortic pressure and clinical outcomes: principal results of the Conduit Artery Function Evaluation (CAFE) study. Circulation 113, 1213–1225 (2006).
Google Scholar
-
Domanski, M. J., Davis, B. R., Pfeffer, M. A., Kastantin, M. & Mitchell, G. F. Isolated systolic hypertension: prognostic information provided by pulse pressure. Hypertension 34, 375–380 (1999).
Google Scholar
-
Fyhrquist, F. et al. Pulse pressure and effects of losartan or atenolol in patients with hypertension and left ventricular hypertrophy. Hypertension 45, 580–585 (2005).
Google Scholar
-
Gupta, A. et al. Long-term mortality after blood pressure-lowering and lipid-lowering treatment in patients with hypertension in the Anglo-Scandinavian Cardiac Outcomes Trial (ASCOT) Legacy study: 16-year follow-up results of a randomised factorial trial. Lancet 392, 1127–1137 (2018).
Google Scholar
-
Hjalmarson, Å. et al. Effects of controlled-release metoprolol on total mortality, hospitalizations, and well-being in patients with heart failure: the metoprolol CR/XL randomized intervention trial in congestive heart failure (MERIT-HF). J. Am. Med. Assoc. 283, 1295–1302 (2000).
Google Scholar
-
Packer, M. et al. Effect of carvedilol on survival in severe chronic heart failure. N. Engl. J. Med. 344, 1651–1658 (2001).
Google Scholar
-
Flather, M., Shibata, M. & Coats, A. Randomized trial to determine the effect of nebivolol on mortality and cardiovascular hospital admission in elderly patients with heart failure (SENIORS). Eur. Hear. J. 26, 215–225 (2005).
Google Scholar
-
Swedberg, K. et al. Ivabradine and outcomes in chronic heart failure (SHIFT): a randomised placebo-controlled study. Lancet 376, 875–885 (2010).
Google Scholar
-
von der Heyde, B. et al. Translating GWAS-identified loci for cardiac rhythm and rate using an in vivo image- and CRISPR/Cas9-based approach. Sci. Rep. 10, 1–18 (2020).
Google Scholar
-
Jensen, M. T. et al. Heritability of resting heart rate and association with mortality in middle-aged and elderly twins. Heart 104, 30–36 (2018).
Google Scholar
-
Russell, M. W., Law, I., Sholinsky, P. & Fabsitz, R. R. Heritability of ECG measurements in adult male twins. J. Electrocardiol. 30, 64–68 (1998).
Google Scholar
-
De Geus, E. J. C., Kupper, N., Boomsma, D. I. & Snieder, H. Bivariate genetic modeling of cardiovascular stress reactivity: does stress uncover genetic variance? Psychosom. Med. 69, 356–364 (2007).
Google Scholar
-
Petersen, B. S., Fredrich, B., Hoeppner, M. P., Ellinghaus, D. & Franke, A. Opportunities and challenges of whole-genome and -exome sequencing. BMC Genet. 18, 65–83 (2017).
Google Scholar
-
Bycroft, C. et al. The UK Biobank resource with deep phenotyping and genomic data. Nature 562, 203–209 (2018).
Google Scholar
-
Zheng, J. et al. LD Hub: a centralized database and web interface to perform LD score regression that maximizes the potential of summary level GWAS data for SNP heritability and genetic correlation analysis. Bioinformatics 33, 272–279 (2017).
Google Scholar
-
Buniello, A., MacArthur, J. & Cerezo, M. The NHGRI-EBI GWAS Catalog of published genome-wide association studies, targeted arrays and summary statistics 2019. Nucleic Acids Res. 47, D1005–D1012 (2019).
Google Scholar
-
Stelzer, G. et al. The GeneCards suite: from gene data mining to disease genome sequence analyses. Curr. Protoc. Bioinform. 2016, 1.30.1–1.30.33 (2016).
-
Liu, X., Wu, C., Li, C. & Boerwinkle, E. dbNSFP v3.0: a one-stop database of functional predictions and annotations for human nonsynonymous and splice-site SNVs. Hum. Mutat. 37, 235–241 (2016).
Google Scholar
-
Aguet, F. et al. Genetic effects on gene expression across human tissues. Nature 550, 204–213 (2017).
Google Scholar
-
Qi, T. et al. Identifying gene targets for brain-related traits using transcriptomic and methylomic data from blood. Nat. Commun. 9, 2282 (2018).
Google Scholar
-
Westra, H.-J. et al. Systematic identification of trans eQTLs as putative drivers of known disease associations. Nat. Genet. 45, 1238–1243 (2013).
Google Scholar
-
Lloyd-Jones, L. R. et al. The genetic architecture of gene expression in peripheral blood. Am. J. Hum. Genet. 100, 228–237 (2017).
Google Scholar
-
van Rossum, G. & de Boer, J. Interactively testing remote servers using the python programming language. CWI Q. 4, 283–303 (1991).
Google Scholar
-
Shannon, P. et al. Cytoscape: a software environment for integrated models of biomolecular interaction networks. Genome Res. 13, 2498–2504 (2003).
Google Scholar
-
Zhang, H., Wheeler, W., Song, L. & Yu, K. Proper joint analysis of summary association statistics requires the adjustment of heterogeneity in SNP coverage pattern. Br. Bioinform. 19, 1337–1343 (2018).
Google Scholar
-
Stang, A. et al. Algorithms for converting random-zero to automated oscillometric blood pressure values, and vice versa. Am. J. Epidemiol. 164, 85–94 (2006).
Google Scholar
-
Tobin, M. D., Sheehan, N. A., Scurrah, K. J. & Burton, P. R. Adjusting for treatment effects in studies of quantitative traits: antihypertensive therapy and systolic blood pressure. Stat. Med. 24, 2911–2935 (2005).
Google Scholar
-
Nikpay, M. et al. A comprehensive 1000 Genomes-based genome-wide association meta-analysis of coronary artery disease. Nat. Genet. 47, 1121–1130 (2015).
Google Scholar
-
Christophersen, I. E. et al. Large-scale analyses of common and rare variants identify 12 new loci associated with atrial fibrillation. Nat. Genet. 49, 946–952 (2017).
Google Scholar
-
Loh, P.-R. et al. Efficient Bayesian mixed-model analysis increases association power in large cohorts. Nat. Genet. 47, 284–290 (2015).
Google Scholar
-
Li, Y., Willer, C. J., Ding, J., Scheet, P. & Abecasis, G. R. MaCH: using sequence and genotype data to estimate haplotypes and unobserved genotypes. Genet. Epidemiol. 34, 816–834 (2010).
Google Scholar
-
Howie, B., Fuchsberger, C., Stephens, M., Marchini, J. & Abecasis, G. R. Fast and accurate genotype imputation in genome-wide association studies through pre-phasing. Nat. Genet. 44, 955 (2012).
Google Scholar
-
Fuchsberger, C., Abecasis, G. R. & Hinds, D. A. minimac2: faster genotype imputation. Bioinformatics 31, 782 (2015).
Google Scholar
-
Howie, B. N., Donnelly, P. & Marchini, J. A flexible and accurate genotype imputation method for the next generation of Genome-Wide Association Studies. PLoS Genet. 5, e1000529 (2009).
Google Scholar
-
Halekoh, U., Højsgaard, S. & Yan, J. The R package geepack for generalized estimating equations. J. Stat. Softw. 15, 1–11 (2006).
Google Scholar
-
Aulchenko, Y. S., Struchalin, M. V. & van Duijn, C. M. ProbABEL package for genome-wide association analysis of imputed data. BMC Bioinforma. 11, 1–10 (2010).
Google Scholar
-
O’connell, J. R. Mixed Model Analysis for Pedigree and population (MMAP). https://doi.org/10.5281/zenodo.5033491 (2017).
-
Willer, C. J., Li, Y. & Abecasis, G. R. METAL: fast and efficient meta-analysis of genomewide association scans. Bioinformatics 26, 2190–2191 (2010).
Google Scholar
-
Purcell, S. et al. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am. J. Hum. Genet. 81, 559–575 (2007).
Google Scholar
-
Verweij, N., Van De Vegte, Y. J. & Van Der Harst, P. Genetic study links components of the autonomous nervous system to heart-rate profile during exercise. Nat. Commun. 9, 898 (2018).
Google Scholar
-
Chow, G. C. Tests of equality between sets of coefficients in two linear regressions. Econometrica 28, 591 (1960).
Google Scholar
-
Palmer, T. M. et al. Using multiple genetic variants as instrumental variables for modifiable risk factors. in. Stat. Methods Med. Res. 21, 223–242 (2012).
Google Scholar
-
Teslovich, T. M. et al. Biological, clinical and population relevance of 95 loci for blood lipids. Nature 466, 707–713 (2010).
Google Scholar
-
Hemani, G. et al. The MR-base platform supports systematic causal inference across the human phenome. Elife 7, e34408 (2018).
Google Scholar
-
Hemani, G., Tilling, K. & Davey Smith, G. Orienting the causal relationship between imprecisely measured traits using GWAS summary data. PLoS Genet. 13, e1007081 (2017).
Google Scholar
-
Lee, S. H., Goddard, M. E., Wray, N. R. & Visscher, P. M. A better coefficient of determination for genetic profile analysis. Genet. Epidemiol. 36, 214–224 (2012).
Google Scholar
-
Bowden, J. et al. A framework for the investigation of pleiotropy in two-sample summary data Mendelian randomization. Stat. Med. 36, 1783–1802 (2017).
Google Scholar
-
Greco M, F., Del, Minelli, C., Sheehan, N. A. & Thompson, J. R. Detecting pleiotropy in Mendelian randomisation studies with summary data and a continuous outcome. Stat. Med. 34, 2926–2940 (2015).
Google Scholar
-
Bowden, J., Davey Smith, G. & Burgess, S. Mendelian randomization with invalid instruments: effect estimation and bias detection through Egger regression. Int. J. Epidemiol. 44, 512–525 (2015).
Google Scholar
-
Bowden, J. et al. Assessing the suitability of summary data for two-sample Mendelian randomization analyses using MR-Egger regression: the role of the I2 statistic. Int. J. Epidemiol. 45, dyw220 (2016).
Google Scholar
-
Rees, J. M. B., Wood, A. M., Dudbridge, F. & Burgess, S. Robust methods in Mendelian randomization via penalization of heterogeneous causal estimates. PLoS ONE 14, e0222362 (2019).
Google Scholar
-
Burgess, S., Foley, C. N., Allara, E., Staley, J. R. & Howson, J. M. M. A robust and efficient method for Mendelian randomization with hundreds of genetic variants. Nat. Commun. 11, 1–11 (2020).
Google Scholar
-
Staley, J. R. & Burgess, S. Semiparametric methods for estimation of a nonlinear exposure–outcome relationship using instrumental variables with application to Mendelian randomization. Genet. Epidemiol. 41, 341–352 (2017).
Google Scholar
-
Burgess, S., Davies, N. M. & Thompson, S. G. Instrumental variable analysis with a nonlinear exposure–outcome relationship. Epidemiology 25, 877–885 (2014).
Google Scholar
-
Sanderson, E., Davey Smith, G., Windmeijer, F. & Bowden, J. An examination of multivariable Mendelian randomization in the single-sample and two-sample summary data settings. Int. J. Epidemiol. 48, 713–727 (2019).
Google Scholar
-
Rees, J. M. B., Wood, A. M. & Burgess, S. Extending the MR-Egger method for multivariable Mendelian randomization to correct for both measured and unmeasured pleiotropy. Stat. Med. 36, 4705–4718 (2017).
Google Scholar
-
Grant, A. J. & Burgess, S. Pleiotropy robust methods for multivariable Mendelian randomization. Stat. Med. 40, 5813–5830 (2021).
-
Yavorska, O. O. & Burgess, S. MendelianRandomization: an R package for performing Mendelian randomization analyses using summarized data. Int. J. Epidemiol. 46, 1734–1739 (2017).
Google Scholar
-
Nolte, I. M. et al. Missing heritability: is the gap closing? An analysis of 32 complex traits in the Lifelines Cohort Study. Eur. J. Hum. Genet. 25, 877–885 (2017).
Google Scholar
Acknowledgements
We thank all participants for their participation and valuable contributions. This research has been conducted using the UK Biobank Resource under application number 12010. The work of N.V. was supported by NWO VENI grant 016.186.125. We thank 23andMe and the 23andMe Research Team for their contribution sharing their data and performing the GWAS analysis in the 23andMe cohort. P.V. received an unrestricted grant from GlaxoSmithkline to build the CoLaus study. N.J.T. is a Wellcome Trust Investigator (202802/Z/16/Z), is the PI of the Avon Longitudinal Study of Parents and Children (MRC & WT 217065/Z/19/Z), is supported by the University of Bristol NIHR Biomedical Research Centre (BRC-1215-2001), the MRC Integrative Epidemiology Unit (MC_UU_00011/1) and works within the CRUK Integrative Cancer Epidemiology Program (C18281/A29019). A detailed list of acknowledgements and funding is provided in Supplementary Data 1 per cohort. We also thank all individuals that contributed to the generation of software programs, algorithms and genetic summary statistics. Support for title page creation and format was provided by AuthorArranger, a tool developed at the National Cancer Institute. Authors involved in the funding of the cohorts are listed below. Meta-analyses, Lifelines, PREVEND, UK Biobank: P.v.d.H.; ADDITION-PRO: T.H.; ADVANCE: C.I.; ADVANCE: T.A.; AGES: L.Launer, V.G.; ASCOT: P.Sever, P.B.M.; BC1936: N.G.; BioMe: E.P.B., R.J.F.L.; BRIGHT: P.B.M.; CHS: B.M.P.; CoLaus: P.V.; Croatia-Korcula: O.P., C.H.; DCCT/EDIC: D.R., The DCCT/EDIC Research Group, A.D.P.; DESIR: B.B., P.F.; DGI: L.G.; EPIC-Norfolk: N.J.W.; ERF: C.M.v.D.; Fenland: N.J.W.; FINCAVAS: M.K.; Finrisk: M.P.; FUSION: M.B.; GENOA: P.A.P., S.L.R.K.; GerMIFSs: H.Schunkert, J.E.; GoDARTS: C.N.A.P; GOOD: M.L., C.O.; HBCS: J.G.E.; HERITAGE: T.R., D.C.R., C.B.; HPFS / NHS: P.K.; HRS: D.R.Weir; HYPERGENES: K.S.S., D.C.; InCHIANTI: S.Bandinelli, L.Ferrucci; INGI-CARL: M.P.C.; INGI-FVG: G.G.; JHS: A.Correa; KORA F3: T.M., S.K.; KORA S4: K.Strauch., A.P.; LOLIPOP: J.C.C., J.S.K.; LURIC: W.M.; MESA: J.I.R.; MICROS: A.H.; MPP: O.M.; J.G.S.; NBS: L.A.L.M.K.; NEO: R.d.M.; NESDA: B.W.J.H.P.; NSPHS: Å.J.; ORCADES: J.F.W.; PIVUS: L.L.; PROSPER: P.W.M., J.W.J.; SardiNIA: E.L.L.; SCES: C.Y.C.; SHIP: S.B.F., M.D.; SIMES: T.Y.W.; TRAILS: A.J.O.; TWINS: J.O.; ULSAM: A.P.M., C.Lindgren; YFS: O.T.R., T.L.
Author information
Authors and Affiliations
Consortia
Contributions
Conceptualization: Y.J.v.d.V., R.N.E., M.Y.v.d.E., N.V., P.v.d.H. Methodology, analysis and/or software: Meta-analyses, downstream annotation and Mendelian randomization, Lifelines, PREVEND, UK Biobank: Y.J.v.d.V., R.N.E., M.Y.v.d.E., Y.P.H., M.A.S., N.V., P.v.D.H.; 23andMe: 23andMe Research Team; ADDITION-PRO: Y.Mahendran; ADVANCE: E.S.; AGES: A.V.S.; ALSPAC: V.Y.T, N.J.T.; ARIC: D.E.A., P.S.d.V.; ARIC: A.C.M.; ASCOT: I.N., P.B.M.; B58C: D.P.S.; BC1936: E.V.A.; BioMe: C.Schurmann; BRIGHT: I.N., P.B.M.; CHS: J.A.B.; CoLaus: R.R., P.V.; Croatia-Korcula: O.P., C.H.; DCCT/EDIC: D.R., A.D.P.; DECODE: G.Sveinbjornsson, H.H, D.F.G, D.O.A.; DESIR: C.Lecoeur; DGI: C.Ladenvall; EPIC-Norfolk: J.H.Z., N.J.W.; ERF: A.I., C.T.S., C.M.v.D.; FamHS: L.W., M.F.F.; Fenland: J.Luan, N.J.W.; FHS: S.J.H, C.J.O.; FINCAVAS: N.M.; Finrisk: K.A., P.S.; FUSION: A.U.J.; GENOA: L.F.B.; GerMIFSs: L.Z.; GoDARTS: N.Shah; GOOD: M.N.; HBCS: J.Lahti; HERITAGE: T.R., D.C.R., C.B.; HNR: S.Pechlivanis; HPFS/NHS: L.Q., P.K., M.C.C.; HRS: W.Zhao, J.A.S., J.D.F.; HYPERGENES: F.R., D.C.; InCHIANTI: T.T.; INGI-CARL: A.R, M.P.C, S.U.; INGI-FVG: M.C.; JHS: L.Lange; KORA F3: M.M.N.; KORA S4: C.R., M.F.S.; LOLIPOP: W.Zhang; LURIC: M.E.K., G.E.D.; MESA: X.G., J.Y.; MICROS: F.P., L.Foco; MPP: J.G.S.; NBS: T.E.G.; NEO: R.N., R.d.M., D.O.M.K.; NESDA: Y.Milaneschi, E.J.C.d.G.; NSPHS: Å.J., U.G.; ORCADES: K.E.S., P.K.J.; Other contributors (non-affliated to a cohort): S.Burgess; PIVUS: M.d.H.; POPGEN: F.D.; PROSPER: S.T.; RS: M.E.v.d.B., M.E.; SardiNIA: G.P., K.V.T.; SCES: Y.C.T.; SHIP: S.W.; SIMES: X.S.S.; E.S.T.; SINDI: H.L.L.; D.Q.Q.; TRAILS: P.J.v.d.M.; TWINS: I.M.N.; YFS: L.P.L.; Resources (study management, subject recruitment and genotyping): Meta-analyses, Lifelines, PREVEND, UK Biobank: Y.J.v.d.V., R.N.E., M.Y.v.d.E., Y.P.H., N.V., P.v.d.H.; 23andMe: 23andMe Research Team; ADDITION-PRO: D.R.Witte, T.H.; ADVANCE: C.I, T.A., AGES: L.Launer, V.G.; ALSPAC: S.M.R., N.J.T.; ARIC: D.E.A.; ASCOT: P.Sever, P.B.M.; B58C: D.P.S.; BC1936: A.L., N.G.; BioMe: C.Schurmann, E.P.B., R.J.F.L.; BRIGHT: S.P., P.B.M.; CHS: B.M.P., S.R.H.; CoLaus: R.R., P.V.; Croatia-Korcula: O.P., I.K., C.H.; DCCT/EDIC: The DCCT/EDIC Research Group; DECODE: H.H., D.O.A.; DESIR: B.B., P.F.; DGI: L.G.; EPIC-Norfolk: J.H.Z., N.J.W.; ERF: A.I., C.M.v.D.; FamHS: L.W., M.F.F.; Fenland: J.Luan; N.J.W.; FHS: S.J.H., C.H.N.C., C.J.O.; FINCAVAS: N.M.; K.N., M.K.; Finrisk: M.P.; FUSION: K.L.M., M.B.; GENOA: P.A.P., S.L.R.K.; GerMIFSs: H.Schunkert, J.E.; GoDARTS: C.N.A.P; GOOD: M.L., C.O.; GS:SFHS: A.Campbell, S.Padmanabhan, D.J.P.; HBCS: J.Lahti., J.G.E.; HERITAGE: T.R., D.C.R., C.B.; HNR: S.M.; HPFS / NHS: P.K., M.C.C.; HRS: W.Zhao, J.A.S., J.D.F., D.R.Weir.; HYPERGENES: F.R., K.S.S., D.C.; InCHIANTI: S.Bandinelli, L.Ferrucci; INGI-CARL: A.R., S.U.; INGI-FVG: M.C., G.Sinagra, G.G.; JHS: A.Correa; KORA F3: M.M.N., M.W., T.M., S.K.; KORA S4: K.Strauch, A.P.; LOLIPOP: J.C.C., J.S.K.; LURIC: M.E.K., W.M.; MESA: K.D.T., J.I.R.; MICROS: A.H.; MPP: O.M., J.G.S.; NBS: T.E.G., J.d.G., L.A.L.M.K.; NEO: R.d.M., D.O.M.K.; NESDA: Y.Milaneschi, B.W.J.H.P.; NSPHS: Å.J., U.G.; ORCADES: J.F.W.; PIVUS: L.L., J.S.; POPGEN: A.F., W.L.; PROSPER: S.T., P.W.M., J.W.J.; SardiNIA: E.L.L.; SCES: Y.C.T., N.T., C.Y.C.; SHIP: S.W., M.D.; SIMES: E.S.T., T.Y.W.; SINDI: D.Q.Q., C.Sabanayagam; TRAILS: H.Snieder, A.J.O.; TWINS: I.M.N., J.O., H.R.; ULSAM: A.P.M., C.Lindgren, M.I.; YFS: L.P.L., O.T.R., T.L.; Data curation: R.N.E., Y.J.v.d.V., Y.P.H., M.Y.v.d.E., N.V., P.v.d.H. Writing – Original Draft: Y.J.v.d.V., R.N.E., M.Y.v.d.E., N.V., P.v.d.H. Interpretation of data: Meta-analyses, Lifelines, PREVEND, UK Biobank: Y.J.v.d.V., R.N.E., M.Y.v.d.E., Y.P.H., N.V., P.v.d.H.; ADDITION-PRO: Y.Mahendran, T.H.; ADVANCE: E.S., T.A.; AGES: A.V.S.; ALSPAC: V.Y.T, N.J.T.; ARIC: D.E.A., P.S.d.V., A.C.M.; B58C: D.P.S.; BC1936: E.V.A., N.G.; BioMe: C.Schurmann, E.P.B., R.J.F.L.; CHS: J.A.B., N.Sotoodehnia, B.M.P., S.R.H.; CoLaus: R.R.; Croatia-Korcula: O.P., I.K., C.H.; DCCT/EDIC: D.R., A.D.P.; DECODE: G.Sveinbjornsson, H.H., D.F.G., D.O.A., K.Stefansson; DGI: C.Ladenvall; EPIC-Norfolk: J.H.Z., N.J.W.; ERF: A.I.; C.M.v.D.; FamHS: M.F.F.; Fenland: J.Luan, N.J.W.; FHS: S.J.H., C.J.O.; Finrisk: K.A. P.S., M.P.; GENOA: L.F.B., P.A.P.; GerMIFSs: H.Schunkert, J.E.; GoDARTS: N.Shah, C.N.A.P; HBCS: J.Lahti., J.G.E.; HERITAGE: T.R., D.C.R., C.B.; HYPERGENES: D.C.; InCHIANTI: T.T., S.Bandinelli, L.Ferrucci; JHS: L.Lange, A.Correa; KORA F3: M.M.N., M.W.; KORA S4: C.R., M.F.S.; LURIC: W.M.; MESA: X.G., H.J.L., K.D.T., J.I.R.; MPP: J.G.S.; NESDA: B.W.J.H.P., Å.J.; NSPHS: U.G.; Other contributors (non-affliated to a cohort): S.Burgess; PIVUS: M.d.H.; SardiNIA: K.T.V., E.L.L.; SHIP: S.W.; SIMES: X.S.S.; SINDI: H.L.L.; TRAILS: H.Snieder; TWINS: I.M.N.; ULSAM: A.P.M., C. Lindgren. Review & editing: All authors reviewed and had the opportunity to comment on the manuscript. Visualization: Y.J.v.d.V., N.V., R.N.E., Y.P.H., M.A.S.
Corresponding author
Ethics declarations
Competing interests
N.V. is currently employed at Regeneron plc. The 23andMe Research team members are current or former employees of 23andMe, Inc. and hold stock or stock options in 23andMe. P. Sever has received research awards from Pfizer Inc. I.N. is now a full-time employee at Gilead. B.M.P. serves on the Steering Committee of the Yale Open Data Access Project funded by Johnson & Johnson. K.S., H.H., D.F.G., D.O.A., and G.S. are employees of deCODE genetics/Amgen Inc. C.R. is currently employed at the Broad institute and is supported by a grant from Bayer AG to the Broad Institute focused on the development of therapeutics for cardiovascular disease. M.L. receives consulting or lecturing fees from Amgen, Astellas, UCB, Consilient Health, GE/Lunar, Tromp/Hologic, Renapharma, Meda/Mylan, Janssen-Cilag and Radius Health. W.M. is employed with Synlab Holding Deutschland GmbH. M.E.K. is employed with Synlab Holding Deutschland GmbH and reports grants and personal fees from AMGEN, BASF, Sanofi, Siemens Diagnostics, Aegerion Pharmaceuticals, Astrazeneca, Danone Research, Numares, Pfizer, Hoffmann LaRoche; personal fees from MSD, Alexion; grants from Abbott Diagnostics, all outside the submitted work. The remaining authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Ruth McPherson and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary Information
Peer Review File
Description of Additional Supplementary Files
Supplementary Data 1-31
Reporting Summary
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Reprints and Permissions
About this article
Cite this article
van de Vegte, Y.J., Eppinga, R.N., van der Ende, M.Y. et al. Genetic insights into resting heart rate and its role in cardiovascular disease.
Nat Commun 14, 4646 (2023). https://doi.org/10.1038/s41467-023-39521-2
-
Received: 06 June 2022
-
Accepted: 16 June 2023
-
Published: 02 August 2023
-
DOI: https://doi.org/10.1038/s41467-023-39521-2
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.