
Cardiovascular
Predicting unplanned readmission due to cardiovascular disease in hospitalized patients with cancer: a machine learning approach
Aug
Abstract
Cardiovascular disease (CVD) in cancer patients can affect the risk of unplanned readmissions, which have been reported to be costly and associated with worse mortality and prognosis. We aimed to demonstrate the feasibility of using machine learning techniques in predicting the risk of unplanned 180-day readmission attributable to CVD among hospitalized cancer patients using the 2017–2018 Nationwide Readmissions Database. We included hospitalized cancer patients, and the outcome was unplanned hospital readmission due to any CVD within 180 days after discharge. CVD included atrial fibrillation, coronary artery disease, heart failure, stroke, peripheral artery disease, cardiomegaly, and cardiomyopathy. Decision tree (DT), random forest, extreme gradient boost (XGBoost), and AdaBoost were implemented. Accuracy, precision, recall, F2 score, and receiver operating characteristic curve (AUC) were used to assess the model’s performance. Among 358,629 hospitalized patients with cancer, 5.86% (n = 21,021) experienced unplanned readmission due to any CVD. The three ensemble algorithms outperformed the DT, with the XGBoost displaying the best performance. We found length of stay, age, and cancer surgery were important predictors of CVD-related unplanned hospitalization in cancer patients. Machine learning models can predict the risk of unplanned readmission due to CVD among hospitalized cancer patients.
Introduction
Cardio-oncology is an emerging field for improving screening, prevention, and management of cardiovascular diseases (CVD) that are caused by various pathophysiological mechanisms in cancer patients1. Growing evidence suggests that cancer and CVD have various overlapping risk factors or underlying mechanisms2,3,4, and cancer treatments can be associated with developing a wide spectrum of CVD (e.g., arrhythmia, coronary artery disease, heart failure, peripheral artery disease, or stroke)4,5,6.
In terms of quality of care, unplanned readmission has become a well-recognized objective metric in healthcare. CVD in cancer patients can affect the risk of unplanned readmissions, which have been reported to be costly and associated with worse mortality and prognosis in cancer patients7,8. To facilitate value-driven healthcare decision making to implement cardioprotective strategies or to adjust interventions, there is a need to identify cancer patients who are at a higher risk of unplanned CVD readmission. However, there is currently no risk prediction model for unplanned CVD readmission in cancer patients.
In earlier studies, machine learning (ML) approaches have been shown to improve the prediction of CVD risk and incidence over traditional CVD risk scores (e.g., scores from the American College of Cardiology or the American Heart Association), which may be driven by the flexibility of ML models9,10. Additionally, a variety of ML algorithms have been used in predicting CVD and CVD-related hospitalizations10,11. Therefore, we hypothesized that ML methods could likely provide reliable predictive information about the future risk of unplanned CVD readmissions in cancer patients.
Therefore, using hospital discharge data, we aimed to demonstrate the feasibility of using ML techniques in predicting the risk of unplanned readmission due to CVD among hospitalized cancer patients. In addition, the secondary objective is to compare the predictive performance of different ML algorithms and identify the important risk factors contributing more to the model prediction performance. Based on the previous study reporting the period of increased CVD risk in cancer patients12,13, we used a risk of 180-day readmission for CVD to fully capture the elevated risk of CVD among cancer patients.
Methods
Data source and study population
We retrieved the information of hospitalized patients with a primary diagnosis of cancer (Clinical Classifications Software Refined categories of NEO001-NEO071) from the 2017 and 2018 Nationwide Readmissions Database (NRD). The NRD is designed to generate nationally representative estimates of hospital readmissions and is part of the Healthcare Cost and Utilization Project (HCUP) that is sponsored by the Agency for Healthcare Research and Quality14. All methods were carried out in accordance with relevant guidelines and regulations. Because HCUP-NRD is publicly available deidentified data, the Institutional Review Board of The University of Texas at Austin exempted the study and informed consent was not required.
Patients younger than 18 years of age, patients with any listed diagnosis of CVD (atrial fibrillation, coronary artery disease, heart failure, stroke, peripheral artery disease, cardiomegaly, and cardiomyopathy) or who died in the index hospitalization for cancer, patients with missing values in features, or patients discharged between July and December (as these hospitalizations would lack a minimum 180-day follow-up data) were excluded. Supplementary Fig. 1 depicts the sample selection flow.
Outcomes
Our primary outcome was an unplanned CVD readmission event within 180 days after the index hospitalization for cancer. Unplanned readmissions were identified by excluding elective readmissions using the elective variable in the database. International Classification of Disease, Tenth Revision, Clinical Modification (ICD-10-CM) codes were used to define CVD, including atrial fibrillation (I48), coronary artery disease (I20–I25, I252), cardiomegaly (I517), cardiomyopathy (I43, I427, I429, I420, I425), heart failure (I50), peripheral artery disease (I70, I74, I739), and stroke (I60–I63, I65–I66, I69, I672, I679, I6781–I6782)15.
Features (predicting variables)
We included features that are commonly applied in related studies to predict risk of readmission: age; sex; median household income level; primary payer; All Patient Refined DRG (APR-DRG): risk of mortality subclass; APR-DRG: severity of illness subclass; weekend index admission; Elixhauser index for the risk of readmission16; length of stay and cost of index admission; hospital bed size; smoking; hyperlipidemia; previous percutaneous coronary intervention (PCI); previous coronary artery bypass graft (CABG); previous transient ischemic attack (TIA) or stroke; thrombocytopenia; chronic renal failure; anemia; coagulopathies; liver disease; long term (current) use of anticoagulation; long term (current) use of antithrombotics or antiplatelets; cancer surgery; radiation; chemotherapy; metastasis; and cancer types (i.e., colorectal, lung/bronchus, melanoma, breast, uterus, prostate, bladder, kidney/ureter/renal pelvis, non-Hodgkin lymphoma, leukemia, and other).
Machine learning algorithms
To build the prediction models, we used four commonly used tree-based ML algorithms: decision tree, AdaBoost, extreme gradient boosting (XGBoost), and random forest. We chose these four algorithms because these have been applied commonly and performed well in the CVD research field10. Decision tree is a classifier that is constructed by repeatedly splitting the training set using features to predict the class labels17. AdaBoost is an ensemble classifier that trains weak classifiers and improves the performance of these classifiers by increasing the weight of misclassified samples as the steps progress17,18,19. The XGBoost is an ensemble classifier that successively trains weak classifiers to correct the errors of the last prediction until there is no further improvement17,20. Random forest is an ensemble classifier that trains multiple weak classifiers by repeating random sampling for predictors and observations; the final outcome is determined by a majority vote method18,20,21. The models were built using Python (version 3.9.12; Python Software Foundation) and several Python modules (numpy, pandas, matplotlib, sklearn, imblearn, and xgboost).
As shown in Table 1, our dataset was highly imbalanced, with only 21,021 (5.86%) CVD readmissions after the index admission for cancer. We used the cost-sensitive learning approach to deal with imbalanced data in our study22,23. For the analyses, we considered unplanned readmissions related to a composite of CVD, which included atrial fibrillation (6623 cases), coronary artery disease (7313 cases), cardiomegaly (367 cases), cardiomyopathy (1169 cases), heart failure (5782 cases), peripheral artery disease (2034 cases), and stroke (4508 cases). The hyperparameter search spaces for each model and the best hyperparameters resulting in the highest performance on the test set are shown in Table 2. The feature selection method using L1 penalty is implemented to identify the best set of features.
Evaluation of predictive model performance
To evaluate the performance of each model in predicting unplanned CVD readmission within 180 days, we calculated four performance evaluation measures (i.e., accuracy, precision, recall, F2 score) in the testing set. The F2 score was calculated using the formula: F2 = (1 + 22) × precision × recall/(22 × precision + recall)24. We used F2 score because recall is more important than precision; for example, missing a false negative patient is more costly in terms of poor prognosis and healthcare expenditure than reviewing a patient classified as false positive24. We also calculated the area under the receiver operator characteristic curve (ROC–AUC) and the area under the precision recall curve (PR–AUC). The precision recall curve is commonly used to evaluate the model performance, especially in studies using imbalanced data20. Using a 5 by 2-fold cross-validation approach, we calculated the performance evaluation measures for the models and conducted a paired Student’s t-test25. The paired Student’s t-test with Bonferroni correction for multiple comparisons was used to test whether the difference in the mean performance of the models was statistically significant25,26. As the hyperparameters were tuned to maximize the AUC, we conducted statistical tests to compare the AUC values between the models. We report the mean and 95% confidence interval (CI) of the performance evaluation measures.
Evaluation of feature importance
We used the SHapley Additive exPlanations (SHAP) approach to rank the importance of features in the model that demonstrated the highest AUC performance27. The SHAP value represents the extent to which a feature contributes to the prediction outcome28. We generated the SHAP feature importance plot, summary plot, and cohort bar plot to visualize the results. The summary plot combined feature importance and feature effects, while the cohort bar plot separated the contribution of each feature between different groups, such as men and women.
Results
Patient characteristics
We identified a total of 358,629 patients hospitalized for cancer between 2017 and 2018 in the US (mean [SD] age, 62.2 [13.4] years; 184,657 female patients [51.5%]), of whom 21,021 (5.9%) were found to have 180-day unplanned CVD readmission. Sample characteristics and information on all features at the time of index hospitalization for cancer were shown in Table 1.
Predictive model performance
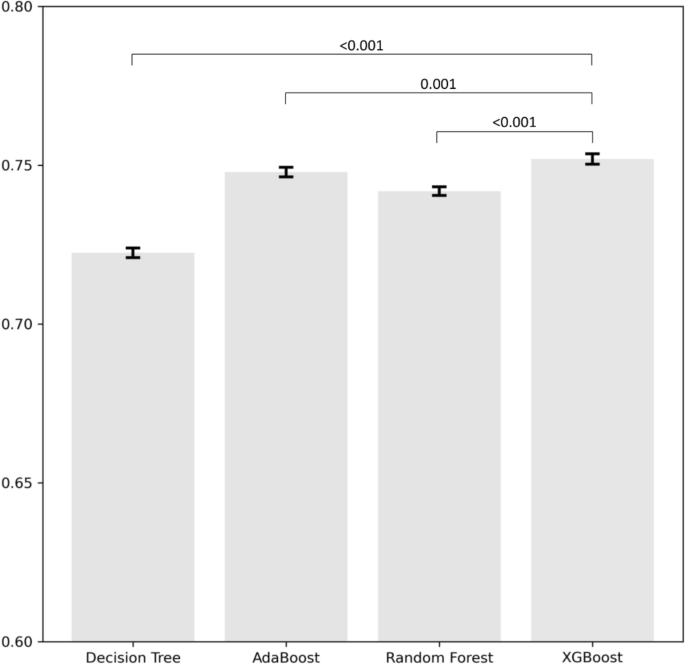
Figure 1 depicts the bar plot showing the mean AUC and 95% confidence intervals obtained from the 5 by 2-fold cross-validation for the various models. The results indicate that the AUC of XGBoost was significantly higher compared to the other methods. The performance of each algorithm in predicting unplanned readmission due to any CVD among patients hospitalized for cancer was shown in Table 3. Compared to other ML algorithms, the XGBoost approach achieved the highest AUC in both the ROC curve (0.75) and PR curve (0.15), followed by the AdaBoost (ROC–AUC, 0.75; PR–AUC, 0.15) and random forest (ROC–AUC, 0.74; PR–AUC, 0.14), while the decision tree had the lowest AUC (ROC–AUC, 0.72; PR–AUC, 0.13) (Table 3).
Average area under the curve of the different models using 5 by 2-fold cross-validation. Error bars represent 95% confidence intervals across folds. Comparisons were conducted between XGBoost and three different models.
Feature importance
In Fig. 2, we present the SHAP feature importance and summary plot of the top ten features from the XGBoost model, which demonstrate its superior performance in terms of AUC. Among the top ten predictors based on the feature importance, length of stay was identified as the most important predictor, followed by age and cancer surgery. A shorter length of stay, higher age, and no cancer surgery during the index hospitalization contribute to a positive prediction of readmission (readmission occurred). Full results for Fig. 2 are given in Supplementary Figs. 2 and 3. In Fig. 3, we present the SHAP cohort bar plots for the subgroups of length of stay, age, cancer surgery, and sex, which are included in the top ten features from the XGBoost model. Some features showed higher importance for specific subgroups in predicting readmissions. For example, the length of stay feature was more important in the higher age group, the group without cancer surgery during the index hospitalization, and men in predicting readmission.

SHAP feature importance and summary plots of the top 10 features from the XGBoost model. (A) SHAP feature importance plot. (B) SHAP summary plot. The features are ordered according to their importance. Length of stay (LOS) was the most important feature. The SHAP value of a feature represents the extent to which this feature contributes to the prediction result. A positive SHAP value for a feature indicates an increased predicted risk of readmission, while a negative SHAP value indicates a decreased predicted risk of readmission. SHAP SHapley Additive exPlanations.

SHAP feature importance by different cohorts. (A) Length of stay. (B) Age. (C) Cancer surgery. (D) Sex. SHAP, SHapley Additive exPlanations.
Discussions
This population-based study applied ML to predict unplanned readmission for CVD after initial hospitalization for cancer and demonstrated that XGBoost showed a comparatively better predictive performance among four commonly used ML algorithms in the CVD research field. Similarly, other studies compared different ML models in predicting unplanned readmissions using electronic health records or registry data, and XGBoost outperformed the other ML models29,30,31. Our results add to the literature suggesting that XGBoost could be a promising model for predicting the risks of readmissions regardless of the data type.
ML has been tested on several disease states. A few studies used ML to predict various outcomes, including 30-day or 90-day readmissions due to heart failure29,30,32. The studies suggested application of ML in predicting risks for CVD-related readmissions is feasible. Previous studies on cancer made use of ML to predict various health outcomes of cancer. A study utilized ML to identify women who were at high risk of developing cervical cancer from screening data collected at a local hospital33. Despite the small sample size, ML accurately identified women who have a risk of developing cervical cancer33. Another study applied ML to predict patients at risk of short-term mortality34. Although the results showed a high risk of bias, ML showed promising performance in predicting short-term mortality in patients34. A mini review has identified past studies used of the application of ML to predict the outcomes of cancer such as susceptibility, recurrence, and survival35. To our knowledge, this study is the first to use ML methods to explore the CVD-related readmissions for patients hospitalized with cancer in the United States. In our study, the best predictive model was based on XGBoost for the readmission. This finding suggests that applying this model to cancer hospitalizations may help identify patients who need follow-up care to prevent readmission.
Previous studies utilizing ML reported similar risk factors to ours for unplanned readmission in cancer patients. An NRD study analyzed patients who underwent spinal surgery for a metastatic spinal column tumor, and deep vein thrombosis (CVD) was one of the top features of importance for unplanned 30-day readmission36. The all-cause unplanned readmission in the study was similar to our feature importances, such as age and kidney disorders36. Another NRD study identified risk factors for early readmission after esophagectomy for curative treatment of early-stage esophageal cancer37. Similar to our findings, Bolourani and colleagues reported that factors such as age and length of stay were the reasons for all-cause 30-day readmission in cases containing atrial fibrillation and coronary artery disease37. A study on hospital-wide all-cause readmission analyzed the electronic health records of 96,550 patients from 205 sites, which provided robust clinical features26. The robustness of features resulted in identifying novel risk factors and protective factors for unplanned readmissions31. In previous studies, it has been reported that cancer patients have a higher overall risk of coronary heart disease and stroke compared to patients without cancer during the first 6 months through 10 years after cancer diagnosis12,13. Our preliminary findings from the HCUP-NRD database have revealed a significantly higher rate of 180-day readmissions among cancer patients compared to non-cancer patients. These findings are currently undergoing revision for submission to Reviews in Cardiovascular Medicine. As a result, we have developed a prediction model for CVD specifically for cancer patients to identify crucial predictors that are relevant to this specific population. Previous evidence suggests that cancer patients may require alternative CVD risk prediction models38. Considering that cancer patients are at a higher risk of developing CVD and associated predictors, these findings offer valuable insights into understanding the crucial factors for predicting CVD readmission in this patient population. Our findings regarding risk factors can guide further research aimed to reduce unplanned readmission rates for cancer patients.
We acknowledge several potential limitations in this study. First, some factors that can be strong predictors of hospital readmission are not available in the NRD, such as cancer stages, chemotherapy regimen information, race/ethnicity, or laboratory test results; thus, the impact of these factors could not be assessed. Future effort can be focused on including more predictors to improve the performance of prediction models. Furthermore, although we employed a knowledge/expert-based approach for feature engineering in this study, future research could benefit from adopting a data/model-driven approach. For instance, utilizing Word2Vec to generate feature vectors from ICD codes could provide a wealth of information to further enhance the analysis39,40. Second, although we tried to solve the data imbalance, the advanced performance may be limited by the small number of CVD readmission events. To improve prediction performance, future research can continue this effort to test and refine the prediction models by trying different sampling methods, different feature sets, or utilizing additional ML algorithms. Third, although the HCUP routinely performs quality control to confirm the validity and consistency of databases41, a possibility of miscoding for cause of readmission may influence the performance of our prediction models. Fourth, we focused only on the 180-day readmission outcome. We developed a prediction model for the occurrence of readmission within 180 days, considering previous evidence indicating that CVD requires a longer follow-up period and that a 180-day timeframe may hold significance12,13,42,43. Additionally, we conducted preliminary analyses, which are currently undergoing revision for submission to the Reviews in Cardiovascular Medicine. These initial findings revealed a significantly higher rate of 180-day CVD readmission among cancer patients compared to non-cancer patients. Although survival analyses have not yet been conducted, we plan to explore this aspect in future research endeavors. Fifth, due to the limited number of occurrences for each individual CVD outcome, we were unable to develop separate prediction models for each CVD outcome. Nevertheless, with the use of population-based data, this study provides insights that may help to guide clinical decisions related to preventive strategies for unplanned CVD readmissions among hospitalized cancer patients.
Conclusions
In conclusion, our study demonstrated the feasibility and performance of the ML approach in predicting the risk of unplanned readmission for CVD after the index hospitalization for cancer. The results suggest that ML, especially XGBoost, can be used as a prognostic prediction model for cancer patients in unplanned care settings in the future. In terms of value-driven healthcare decision making, this study contributes to a better knowledge of the risk prediction of CVD-related unplanned readmissions, which may be used as a basis for facilitating future research on this topic.
Data availability
The data that support the findings of this study are available for purchase from the Central Distributor of the Healthcare Cost and Utilization Project (HCUP). To access the data, other researchers can contact HCUP through the HCUP Central Distributer (https://www.distributor.hcup-us.ahrq.gov) and purchasing the relevant years of HCUP data.
References
-
Chen, H. et al. Artificial intelligence applications in cardio-oncology: Leveraging high dimensional cardiovascular data. Front. Cardiovasc. Med. 9, 941148 (2022).
Google Scholar
-
Koene, R. J., Prizment, A. E., Blaes, A. & Konety, S. H. Shared risk factors in cardiovascular disease and cancer. Circulation 133, 1104–1114 (2016).
Google Scholar
-
Paterson, D. I. et al. Incident cardiovascular disease among adults with cancer: A population-based cohort study. J. Am. Coll. Cardiol. CardioOnc. 4, 85–94 (2022).
-
Ohtsu, H., Shimomura, A. & Sase, K. Real-world evidence in cardio-oncology: What is it and what can it tell us?. Cardio Oncol. 4, 95–97 (2022).
-
Curigliano, G. et al. Management of cardiac disease in cancer patients throughout oncological treatment: ESMO consensus recommendations. Ann. Oncol. 31, 171–190 (2020).
Google Scholar
-
Koutsoukis, A. et al. Cardio-oncology: A focus on cardiotoxicity. Eur. Cardiol. Rev. 13, 64 (2018).
Google Scholar
-
Kohut, A. et al. Evaluating unplanned readmission and prolonged length of stay following minimally invasive surgery for endometrial cancer. Gynecol. Oncol. 156, 162–168 (2020).
Google Scholar
-
Hembree, T. N. et al. Predicting survival in cancer patients with and without 30-day readmission of an unplanned hospitalization using a deficit accumulation approach. Cancer Med. 8, 6503–6518 (2019).
Google Scholar
-
Kakadiaris, I. A. et al. Machine learning outperforms ACC/AHA CVD risk calculator in MESA. J. Am. Heart Assoc. 7, e009476 (2018).
Google Scholar
-
Zhao, Y., Wood, E. P., Mirin, N., Cook, S. H. & Chunara, R. Social determinants in machine learning cardiovascular disease prediction models: A systematic review. Am. J. Prev. Med. 61, 596–605 (2021).
Google Scholar
-
Angraal, S. et al. Machine learning prediction of mortality and hospitalization in heart failure with preserved ejection fraction. JACC: Heart Fail. 8, 12–21 (2020).
Google Scholar
-
Zöller, B., Ji, J., Sundquist, J. & Sundquist, K. Risk of coronary heart disease in patients with cancer: A nationwide follow-up study from Sweden. Eur. J. Cancer 48, 121–128 (2012).
Google Scholar
-
Zöller, B., Ji, J., Sundquist, J. & Sundquist, K. Risk of haemorrhagic and ischaemic stroke in patients with cancer: A nationwide follow-up study from Sweden. Eur. J. Cancer 48, 1875–1883 (2012).
Google Scholar
-
Healthcare Cost and Utilization Project. Introduction to the HCUP Nationwide Readmissions Database (NRD), (2019). Retrieved 9 Aug 2022 from https://www.hcup-us.ahrq.gov/db/nation/nrd/Introduction_NRD_2019.jsp
-
Brown, S.-A. et al. Establishing an interdisciplinary research team for cardio-oncology artificial intelligence informatics precision and health equity. Am. Heart J. Plus: Cardiol. Res. Pract. 13, 100094 (2022).
-
Healthcare Cost and Utilization Project. User guide: Elixhauser comorbidity software refined for ICD-10-CM diagnoses, v2022.1, (2021). Retrieved 20 Sept 2022 from https://www.hcup-us.ahrq.gov/toolssoftware/comorbidityicd10/CMR-User-Guide-v2022-1.pdf
-
Jahan, M. S., Mansourvar, M., Puthusserypady, S., Wiil, U. K. & Peimankar, A. Short-term atrial fibrillation detection using electrocardiograms: A comparison of machine learning approaches. Int. J. Med. Inform. 163, 104790 (2022).
Google Scholar
-
Byeon, H. Exploring factors for predicting anxiety disorders of the elderly living alone in South Korea using interpretable machine learning: A population-based study. Int. J. Environ. Res. Public Health 18, 7625 (2021).
Google Scholar
-
Freund, Y. & Schapire, R. E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 55, 119–139 (1997).
Google Scholar
-
Abe, D. et al. A Prehospital triage system to detect traumatic intracranial hemorrhage using machine learning algorithms. JAMA Netw. Open 5, e2216393 (2022).
Google Scholar
-
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Google Scholar
-
Prusa, J., Khoshgoftaar, T. M., Dittman, D. J. & Napolitano, A. in 2015 IEEE International Conference on Information Reuse and Integration. 197–202 (IEEE).
-
Feng, F., Li, K.-C., Shen, J., Zhou, Q. & Yang, X. Using cost-sensitive learning and feature selection algorithms to improve the performance of imbalanced classification. IEEE Access 8, 69979–69996 (2020).
Google Scholar
-
Zhang, K. & Demner-Fushman, D. Automated classification of eligibility criteria in clinical trials to facilitate patient-trial matching for specific patient populations. J. Am. Med. Inform. Assoc. 24, 781–787 (2017).
Google Scholar
-
Susič, D., Syed-Abdul, S., Dovgan, E., Jonnagaddala, J. & Gradišek, A. Artificial intelligence based personalized predictive survival among colorectal cancer patients. Comput. Methods Progr. Biomed. 231, 107435 (2023).
Google Scholar
-
Moncada-Torres, A., van Maaren, M. C., Hendriks, M. P., Siesling, S. & Geleijnse, G. Explainable machine learning can outperform Cox regression predictions and provide insights in breast cancer survival. Sci. Rep. 11, 6968 (2021).
Google Scholar
-
Lundberg, S. M. & Lee, S.-I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 30 (2017).
-
Pan, X. et al. A survival prediction model via interpretable machine learning for patients with oropharyngeal cancer following radiotherapy. J. Cancer Res. Clin. Oncol. https://doi.org/10.1007/s00432-023-04644-y (2023).
Google Scholar
-
Sarijaloo, F., Park, J., Zhong, X. & Wokhlu, A. Predicting 90 day acute heart failure readmission and death using machine learning-supported decision analysis. Clin. Cardiol. 44, 230–237 (2021).
Google Scholar
-
Ru, B. et al. Comparison of machine learning algorithms for predicting hospital readmissions and worsening heart failure events in patients with heart failure with reduced ejection fraction: Modeling study. JMIR Form. Res. 7, e41775 (2023).
Google Scholar
-
Zhao, P., Yoo, I. & Naqvi, S. H. Early prediction of unplanned 30-day hospital readmission: Model development and retrospective data analysis. JMIR Med. Inform. 9, e16306 (2021).
Google Scholar
-
Wang, Z. et al. Using deep learning to identify high-risk patients with heart failure with reduced ejection fraction. J. Health Econ. Outcomes Res. 8, 6 (2021).
Google Scholar
-
Sun, L. et al. Optimization of cervical cancer screening: A stacking-integrated machine learning algorithm based on demographic, behavioral, and clinical factors. Front. Oncol. 12, 821453 (2022).
Google Scholar
-
Lu, S.-C. et al. Machine learning-based short-term mortality prediction models for patients with cancer using electronic health record data: Systematic review and critical appraisal. JMIR Med. Inform. 10, e33182 (2022).
Google Scholar
-
Kourou, K., Exarchos, T. P., Exarchos, K. P., Karamouzis, M. V. & Fotiadis, D. I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 13, 8–17 (2015).
Google Scholar
-
Elsamadicy, A. A. et al. Utilization of machine learning to model important features of 30-day readmissions following surgery for metastatic spinal column tumors: The influence of frailty. Glob. Spine J. https://doi.org/10.1177/21925682221138053 (2022).
Google Scholar
-
Bolourani, S. et al. Using machine learning to predict early readmission following esophagectomy. J. Thorac. Cardiovasc. Surg. 161, 1926–1939 (2021).
Google Scholar
-
Blaes, A. H. & Shenoy, C. Is it time to include cancer in cardiovascular risk prediction tools?. The Lancet 394, 986–988 (2019).
Google Scholar
-
van Weenen, E. & Feuerriegel, S. in 2020 IEEE International Conference on Big Data (Big Data). 1709–1719 (IEEE).
-
Choi, Y., Chiu, C.Y.-I. & Sontag, D. Learning low-dimensional representations of medical concepts. AMIA Summits Transl. Sci. Proc. 2016, 41 (2016).
Google Scholar
-
Healthcare Cost and Utilization Project. HCUP quality control procedures, (2022). Retrieved 15 Aug 2022 from https://www.hcup-us.ahrq.gov/db/quality.pdf
-
Muhandiramge, J. et al. Cardiovascular disease in adult cancer survivors: A review of current evidence, strategies for prevention and management, and future directions for cardio-oncology. Curr. Oncol. Rep. 24, 1579–1592 (2022).
Google Scholar
-
Oren, O. et al. Cardiovascular health and outcomes in cancer patients receiving immune checkpoint inhibitors. Am. J. Cardiol. 125, 1920–1926 (2020).
Google Scholar
Author information
Authors and Affiliations
Contributions
S.H. and C.P. conceptualized this work, developed the methodology, and conducted the data analysis. C.P. was responsible for data curation. S.H., C.P., and T.J.S. wrote the first draft of the manuscript. S.H., C.P., B.P.N., and T.J.S. interpreted the data and revised and critically reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Supplementary Figures.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Reprints and Permissions
About this article
Cite this article
Han, S., Sohn, T.J., Ng, B.P. et al. Predicting unplanned readmission due to cardiovascular disease in hospitalized patients with cancer: a machine learning approach.
Sci Rep 13, 13491 (2023). https://doi.org/10.1038/s41598-023-40552-4
-
Received: 25 February 2023
-
Accepted: 12 August 2023
-
Published: 18 August 2023
-
DOI: https://doi.org/10.1038/s41598-023-40552-4
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.