
Cardiovascular
Cardiovascular disease behavioural risk factors in rural interventions: cross-sectional study
Aug
Abstract
This study aims to (1) assess the distribution of variables within the population and the prevalence of cardiovascular disease (CVD) behavioural risk factors in patients, (2) identify target risk factor(s) for behaviour modification intervention, and (3) develop an analytical model to define cluster(s) of risk factors which could help make any generic intervention more targeted to the local patient population. Study patients with at least one CVD behavioural risk factor living in a rural region of the Scottish Highlands. The study used the STROBE methodology for cross-sectional studies. Demographic and clinical data of patients (n = 2025) in NHS Highlands hospital were collected at the point of admission for PCI between 04.01.2016 and 31.12.2019. Collected data distributions were analysed by CVD behavioural risk factors for prevalence, associations, and direction of associations. Cluster definition was measured by assignment of a unit score each for the overall level of prevalence and significance of associations, and general logistics modelling for direction and significance of the risk. The mean (SD) age was 69.47(± 10.93) years [95% CI (68.99–69.94)]. The key risk factors were hyperlipidaemia, hypertension, and elevated body mass index (BMI). Approximately 40% of the population have multiple risk factor counts of two. Analytical measures revealed a population risk factor cluster with elevated BMI [77.5% (1570/2025)] that is mostly either hyperlipidaemic [9.43%, co-eff. (17), P = 0.007] or hypertensive [22.72%, co-eff. (17), P = 0.99] as key risk factor clusters. Carefully modelled analyses revealed clustered risk associated with elevated BMI. This information would support a strategy for targeting risk factor clusters in novel interventions to improve implementation efficiency. Exposure to and outcome of an elevated BMI is linked more to the population’s socio-economic outcomes rather than to regional rurality or urbanity.
Introduction
Background
The global burden of cardiovascular diseases (CVD) remains high1. In the UK, 7.4 million people live with CVD and approximately 460 deaths are recorded per day2. This burden accounts for a total annual healthcare cost of £800 million in Scotland2. The main therapeutic procedure for obstructive coronary artery disease is percutaneous coronary intervention (PCI) with over 500 procedures performed annually in the Scottish Highlands3. Despite the increase in annual counts of procedures and repeated sessions, there continue to be significant challenges to access especially in rural regions4.
Cigarette smoking, diabetes, obesity, and hypertension are independent risk factors for CVDs accounting for about 50% of its pathogenesis1,2. Treatment of these risk factors has been proven to reduce the risk of future cardiac events5. It has been predicted that mortality from CVD in the UK could be halved by small changes in cardiovascular disease risk factors—reducing smoking prevalence by 1% could lead to 2000 fewer CVD deaths per year, and a one percent reduction in population diastolic blood pressure could prevent around 1500 CVD deaths each year2. High-risk reduction strategies i.e. multiple risk factor treatment have also been suggested to have a substantial impact in CVD reduction6.
Following a cardiac event such as myocardial infarction or PCI for stable angina, cardiac rehabilitation programmes provide comprehensive rehabilitation in the form of education, exercise sessions, and psychological support. However, the impact of cardiac rehabilitation remains suboptimal due to (1) accessibility, (2) cardio rehabilitation class uptake and adherence, and (3) patient understanding of CVD7. In addition, recent studies have also indicated low rehab support acceptability and lack of completion of classes as major factors among people with lower health literacy8,9. A one-size-fits-all approach further weakens the efficacy of interventions due to the exclusion of patient experience in their design10. Digital technologies (such as software applications, the internet, and wearable sensors) in CVD risk factor modification have been embraced by some individuals as beneficial. They have the potential to overcome some of these challenges by delivering an alternative channel of educating, coaching and training out-patients11. However, digital technologies appear to be weak in reducing unhealthy behaviours linked with CVD risk factor modification when compared to cardiac rehab programmes12.
Several approaches have been used to help modify health behaviour among people with CVD risk factors. Common examples include health training and coaching sessions, health promotion and campaigns, and community-based participatory research13. Storytelling, which is also referred to as a narrative, has historically been used as a means of influencing public opinion and regulating human behaviour. More recently on a digital platform, it has been used for marketing and politics14. Lately, in the health sector, digital storytelling has been used for the modification of health behaviour in clinical trials and interventions especially in ‘remote rural’ and ‘deprived’ populations. Due to the ability to integrate patient experience in its design, digital storytelling has now been indexed as a major approach to different CVD-related risk factor modification.
The generalised approach used in the development of behavioural interventions is not fit for the purpose because it is not cost-efficient in the long term15. Therefore, novel (as well as existing) interventions such as digital storytelling in behavioural risk factor modification could use a methodological assessment or model of risk factors of interest in a specific population to identify which risk factor(s) to target. Such a model could inform a risk factor cluster target, which is geo-localized in its strategic pattern towards a patient-focused approach. This would create an effective targeted behavioural intervention application, in a more efficient and sustainable manner15,16. This study presents an analytical approach, which could be replicated in future intervention designs for different disease populations.
Objectives
This study aims to (1) assess the distribution of variables within the population and the prevalence of CVD risk factors in patients, (2) identify target CVD risk factor(s) for behaviour modification intervention, and (3) develop an analytical model to define cluster(s) of risk factors which could help make any generic intervention more targeted to the local patient population.
Methods
Defining population clusters by cause and effect (outcome) distribution could use various observational study designs such as cohort, case–control, or cross-sectional studies depending on the research focus. A cohort study design distinguishes between cause and effect by studying incidence, causes, and prognosis while a case–control study design seeks to identify possible predictors of an effect (usually a rare effect) by retrospectively comparing groups. However, a cross-sectional study design determines prevalence by simultaneously focusing on cause and effect in time17.
This study intends to model risk factors in clusters to determine how they interact around an outcome of interest, CVDs. This study chose a cross-sectional design because it is cost-efficient, not time-consuming, and does not need participant follow-up; to achieve the aims of the study17.
Study design
This study was designed in line with Strengthening the Reporting of Observational studies in Epidemiology (STROBE) methodology for cross-sectional studies18. The population distribution was analysed for prevalence by gender, exposure to CVD risk factors, and number of risk factor counts. Statistical associations were tested between independent variables and risk factors, and the direction of association was determined.
This study does not require ethical approval or subject consent. However, approval for use of anonymised data was required. This was received from the office of the Caldicott Guardian, NHS Highland. The NHS Scotland guidance and regulation on the use of anonymised data of patients does not require recourse to patients on the use of data for the purpose of clinical research inputs meant for hospital benefits.
Setting
Retrospective data from patients who had undergone PCI at Raigmore Hospital in Inverness, NHS Highland from 4th of January 2016 to 31st of December 2019 were included in the study. Eligible patient’s demographic and clinical data were collected at the point of admission for a PCI.
Participants
Patients who have had at least one elective or emergency PCI.
Variables
Demographic details include age, gender, geographic deprivation groups, economic deprivation ranks, family history of coronary artery disease, and risk factor counts; procedural, administrative, and clinical details such as body mass index, total cholesterol concentration, blood sugar concentration, blood pressure status and smoking status.
Data source and measurements
Age at the time of the data collection was grouped into four ranges: below 40, 40–59, 60–79, and 80 and above years19. Geographic deprivation groups were derived from postcode data-match with the Scottish Index of Multiple Deprivation, SIMD 201920. The SIMD 2019 defines geographical location postcodes in Scotland as six groups: ‘accessible rural’, ‘remote rural’, ‘accessible small towns’, ‘remote small towns’, ‘large urban areas’ or ‘other urban areas’—these groups were re-classified into ‘SIMD groups’ and expressed as ‘urban’, ‘accessible’ and ‘remote’. Economic deprivation ranks were derived from postcode data-match with the Scottish Index of Multiply Deprivation, SIMD 202020. The SIMD 2020 defines geographical location postcodes in Scotland as economic rank 1 (most economically deprived data zone) to rank 6976 (least economically deprived data zone) and classified as ‘SMID ranking’ in quintiles from one to five. BMI ranges were defined using the WHO adults’ BMI classification: underweight (below 18.5), normal weight (18.5–24.9), pre-obesity (25.0–29.9), obesity class I (30.0–34.9), obesity class II (35.0–39.9), obesity class III (above 40)21. These were grouped into ‘low or normal weight’ (≤ 24.9) and ‘elevated BMI’ (≥ 25.0) to capture the preventive and corrective nature of intervention. Cholesterol concentration was defined using the BHF measurement and grouped ≤ 5 mmol/L as healthy and > 5 mmol/L as high22. Blood sugar and blood pressure were qualitatively defined from the original dataset.
Body mass index (BMI) was derived from patients’ weight and height data and measured in kg/m2. All dependent variables (BMI, total cholesterol, blood sugar concentration, and blood pressure) used the National Health Services, NHS Scotland measurement units23. These variables were grouped based on exposure as high cholesterol and healthy cholesterol (cholesterol concentration), diabetic and not diabetic (blood sugar concentration), hypertensive and not hypertensive (blood pressure), elevated BMI and not obese (BMI group), smoking and not smoking (smoking group). Units are available in appendices.
Bias
The study data has a few repeat patient PCI visits resulting in point duplicates. This was noted and reported in the results section. The study data did not provide sufficient detail of collection for the cholesterol variable (for hyperlipidaemic exposure), resulting in missing data > 50%. Fitness analysis was conducted to measure the effect of this bias on concerned variable. Goodness of fit was tested to measure the representativeness of the data.
Data analyses
The distribution of the population by gender was presented in tables. Tests for differences in means (Welch two sample t-tests) and equality of proportions (3-sample prop-tests) were conducted to check for variance between groups. The prevalence of each risk factor by exposure within the population was analysed by proportions. Risk factor counts proportions were reported for each risk factor within the population.
Missing data were checked (missing compare test) for fitness as missing completely at random (MCAR) to validate the nature of missingness in variables with > 10% missing data e.g. hyperlipidaemic variable, for exposure to cholesterol. Goodness of fit (Pearson’s Chi-squared test) was conducted to ascertain the representativeness of the data in the general population.
A test of association was performed (Pearson’s chi-square test) to detect if there was any significant relationship (1) across independent variables (population’s age, gender, deprivation groups, deprivation ranks, and risk factor counts) and CVD behavioural risk factor determinants (for all identified behavioural risk factors), and (2) within CVD behavioural risk factor determinants using a dependent variable of interest as a potential predictor based on initial association and prevalence scores. A unit score was assigned for overall level of prevalence and association significance across all CVD behavioural risk factor determinants. Unit scores were added to ascertain a preferential determinant of choice16,19.
Finally, the direction of risk in association was analysed for a preferred CVD risk factor determinant (general logistics modelling: odds ratio and co-efficient estimates) among notable predictors with significant association scores in order to inform a suggestive clustering for the purpose of targeting intervention design in the whole population.
Continuous data analysis was presented as means ± standard deviations (SD) while categorical data was presented in percentages. Data wrangling and analyses was done using the R Studio Version 1.3.1056 software24. All tests were two-tailed with level of significance set at P < 0.05, and 95% Confidence Interval (CI).
Role of funding source
The sponsors, as acknowledged in this text were not involved in study design; the collection, analysis and interpretation of data, the writing of the report or the decision to submit this paper for publication.
Results
Participants
In total, there were 2,025 patient data with a mean (SD) age 69.47 (± 10.93) years [95% CI, 68.99–69.94]. The women were older compared to men, mean age 71.14(± 11.1) to 68.91(± 10.8) years (P = 0.0001). Detailed characteristics (duplicates and missing data) of participants are described in Table 1.
Data description
Table 1 presents the population demographic and clinical data distribution by gender with P values (t-test and prop-test) for difference in means and equality of proportions. The hyperlipidaemia (cholesterol) variable was marred with missing values by 44% (892 of 2025). Test for fitness (in comparison to independent variables, representative of the population, such as ‘age’ and ‘distance from hospital’) shows that missing data was not MCAR at P < 0.05. Additional fitness check (using the gender variable, which is also representative of the whole population) shows that missing value were not significantly different from observed values for proportions in both male (842 (55.6%), 673 (44.4%)) and female (294 (57.6%), 216 (42.4%)) populations (P = 0.45).
Prevalence of risk factor exposures by independent variables
Table 2 presents the distribution of variables by proportion for CVD risk factor exposures.
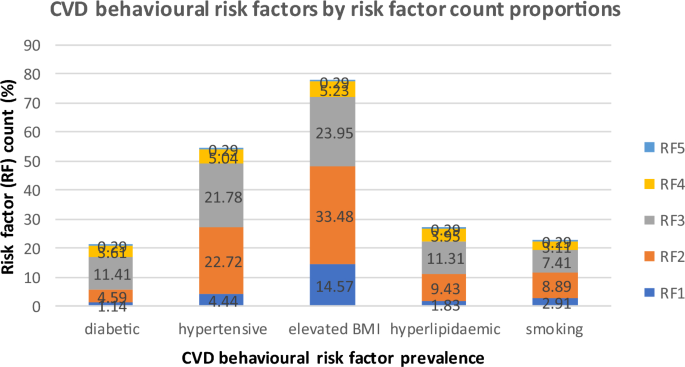
Prevalence of CVD behavioural risk factors by risk factor counts.
Figure 1 presents the prevalence of CVD behavioural risk factors by risk factor counts (multiple exposures within the population).
Prevalence of CVD behavioural risk factors by risk factor counts in the NHS Highlands CVD PCI population, 2016–2019.
Test for association
Table 3 presents the association between independent variables and CVD behavioural risk factor determinants. Association scores and prediction scores are indicated by the counts of significant associations and levels of predictions, respectively.
Test for direction of associations
Table 4 presents a generalised linear model odd ratio and coefficient estimates (where odd ratios were over-estimated) with their respective confidence intervals and p values for exposure to obesity using ‘age’, ‘gender’, ‘family history CAD’, ‘risk factor count’, ‘SIMD groups’ (deprivation groups), and other risk factor determinants as predictors.
Discussion
Key results
This study presents data analyses of CVD risk factors for patients living in a remote region who have undergone PCI over a period of four years. Data duplicates representing about 17% of the population revealed the annual burden of repeated procedures and extent of behaviour change challenge. Results show that elevated BMI (pre-obese and obese status) is the most prevalent CVD risk factor in the population with a significant difference in proportions in both gender (P < 0.0001), followed by hypertension (P = 0.37) and hyperlipidaemia (P < 0.002), with which further analysis shows existence of highest and multiple attributable risk within the population25.
A carefully modelled analyses by assessing overall prevalence, association significance, and direction of risk reveal a population with elevated BMI which is either hyperlipidaemic or hypertensive as clusters of interest for health behaviour change intervention.
Limitation
This study dataset contains some missing data in the ‘cholesterol concentration’ variable, which had a significant count of missing values beyond the 10% theoretically benchmarked for the study. Secondly, the whole dataset is from a single centre and only looked at those who had a PCI intervention, which was not fully representative of the whole exposed population at risk. The bias in these limitations were either provided for or noted with their effects in the study.
Thirdly, the SIMD standard captures data based on area postcode. It is worthy of note that a pocket of individuals might deviate significantly from the general population socio-economic characteristics. However, from a public health perspective, an intervention might be desirable and designed based on the consideration of data from a larger percentage of a population.
Lastly, in addition to these limitations, survivor bias was also noticed. The only group of people that could be included in this study data were individuals who had survived a cardiac event. There is a chance that those who could have benefited from an intervention had died of stroke or myocardial infarction or decided not to go to the hospital after a first cardiac event.
Interpretation
Confounders and determinants
In this study, age and risk factor count variables were significantly associated with all CVD risk factors. Though supported by clinical reports26, further tests indicating the level and direction of association were conducted. They showed that changes in these determinants did not have any effect (OR = 1) on exposure to obesity as a major and dominant CVD risk factor and may therefore be considered confounders within the population—all patients were equally exposed to being obese irrespective of age or number of risk factor counts. This feat agrees with study findings by Ng et al.27. The exposure effect (OR = 1) of risk factor count is validated in that elevated BMI is a dominant risk factor within the population. This, when adjusted for, suggests highest multiple risk association level for obesity compared to other CVD risk factors, an observation similar to study by Mora et al.25.
Association scores (Table 3) showed that gender and SMID group variables merit some discussion. The former as the sole associate with BMI groups and the latter, BMI groups and smoking group, a finding similar to study by Damen et al.28. Lastly, though with lower population proportion, the female gender has higher chance (OR = 3) of being obese compared to the male. This finding validates gender as a determinant of exposure to obesity as also indicated in clinical reports by NHS Scotland23.
Rurality and obesity
In comparing rurality and remoteness, the study results showed that living in a rural area does not completely explain being obese13. The chances (Co-eff = 20, P = 0.99) of being obese in the study population are high and equal for both rural and urban groups—this may be due to inaccessibility to health facilities. This suggests that rural dwellers may not be regionally deprived when compared with their remote urban counterparts within a geographically remote population as also reflected in the study done by Teckle et al.29. However, this finding could not affirm socio-economic status for the study population as the SIMD ranking (a socio-economic variable) did not indicate a significant level of association with all the CVD risk factor determinants except in cholesterol concentration and the smoking group variables. This observation is similar to the Scottish Government report on Tobacco intervention30. It is worthwhile to note that a unit change to geographical accessibility did not have any effect on the chance of being obese. This suggests and affirms that exposure to and outcome of an elevated BMI is linked more to social-economic outcomes rather than to rurality or urbanity as supported in previous studies20,31.
Family history of CAD and obesity
Results showed that having a family history of CAD increases the chance (OR = 3) of being obese and not having a family history of CAD decreases chance (OR = -2) of being obese, an observation similar to studies done by Jin et al.32.
Diabetes and obesity
For this study, the chance of being diabetic increases for individuals with obesity compared to the individuals without obesity, an observation supported in the clinical report by Diabetes, UK26. This association strength is 1.3 times as likely in obese individuals compared to their non-obese counterparts. This is not surprising as obesity is causally linked to diabetes.
Hypertension and obesity
In the blood pressure variable, a unit change in obesity increases the chance (co-eff = 17, P = 0.99) of being hypertensive. To affirm association strength, obese individuals are seventeen times as likely to be hypertensive compared to their non-obese counterparts. This observation on association strength further indicates a stronger level of association between hypertension and elevated BMI within this population compared to any other CVD risk factor. This, therefore, suggests the need for imminent intervention within observed cluster, a suggestion similar to study by Cesana et al.33.
Hyperlipidaemia and obesity
Though with missing at random data within the population, the significant association in the cholesterol concentration variable coupled with association strength for hyperlipidaemia is noticed with the elevated BMI group. This makes hyperlipidaemia and obesity a cluster risk factor of choice as also suggested by Iliodromiti et al.34.
Smoking and obesity
A previous report (2020) on tobacco suggested that the Scottish Government’s intervention(s) already in place to reduce smoking within the study population seems to be increasingly effective30. This suggestion is validated in that the ex-smoker individuals within the non-smoking population has the highest prevalence within the smoking group. This validation appears to be responsible for the higher chance (co-eff. = 23, P = 0.99) of being obese within the non-smoking population compared to the chance (co-eff. = 5, P = 0.006) of being obese in the smoking population as validated in the study by Ginawi et al.35. However, quitting smoking may be responsible for diminishing marginal effect on BMI thus reducing exposure to obesity as also reflected in study by Courtemanche et al.36.
Generalizability
The study dataset is geographically localized—while its model may be considerably replicable for advisory use in public health behavioural risk factor interventions, the data outcomes may not be directly representative of intervention application in regions of the world with different CVD risk factor cluster profile. Studies have shown that CVD risk factor cluster profiles are region-specific37,38. The analytical model in this study could therefore be used to make any generic intervention more targeted to specific local populations.
In addition to this, it is worthy of note that in addition to smoking, behavioural risk factors such as unhealthy diet, alcohol consumption, and physical inactivity are important, and they play significant role and contribution toward exposure to clinical risk factors and CVDs. We suggest that future studies focused on risk factors in rural areas are conducted to provide more knowledge and insight.
Conclusion
Carefully modelled analysis measures revealed clustered population of CVD risk factors with elevated BMI. It is therefore concluded that
-
1.
The knowledge of population cluster structure could strategically and substantially inform cardiac rehabilitation intervention targets by improving implementation efficiency and effectiveness thereby further contributing to reduction in the burden of repeated procedures on existing clinical interventions.
-
2.
Exposure to and outcome of an elevated BMI is linked more to the population’s socio-economic outcomes rather than to regional rurality or urbanity.
Data availability
The use of data was approved by the office of the Caldicott Guardian, NHS Highland. Data sharing is limited to the NHS Highland and University of the Highlands and Islands.
References
-
World Health Organization. Cardiovascular diseases. https://www.who.int/health-topics/cardiovascular-diseases/ (2021).
-
British Heart Foundation. The CVD challenge in the UK—healthcare professionals. https://www.bhf.org.uk/for-professionals/healthcare-professionals/data-and-statistics/the-cvd-challenge (2020).
-
British Cardiovascular Intervention Society. Research. https://www.bcis.org.uk/research/ (2020).
-
Palmer, W. & Rolewicz, L. Rural, remote and at risk: Why rural health services face a steep climb to recovery from Covid-19. Report, Nuffield Trust. https://www.nuffieldtrust.org.uk/research/rural-remote-and-at-risk#partners (2021).
-
Khot, U. N. et al. Prevalence of conventional risk factors in patients with coronary heart disease. J. Am. Med. Assoc. https://doi.org/10.1001/jama.290.7.898 (2003).
Google Scholar
-
Emberson, J. Evaluating the impact of population and high-risk strategies for the primary prevention of cardiovascular disease. Eur. Heart J. https://doi.org/10.1016/j.ehj.2003.11.012 (2004).
Google Scholar
-
Brunner-La Rocca, H. P. et al. Challenges in personalised management of chronic diseases-heart failure as prominent example to advance the care process. EPMA J. https://doi.org/10.1186/s13167-016-0051-9 (2016).
Google Scholar
-
Foster, E. J., Munoz, S.-A., Crabtree, D., Leslie, S. J. & Gorely, T. Barriers and facilitators to participating in cardiac rehabilitation and physical activity in a remote and rural population; a cross-sectional survey. Cardiol. J. https://doi.org/10.5603/cj.a2019.0091 (2019).
Google Scholar
-
Walters, R., Leslie, S. J. & Gorely, T. Defining health literacy in cardiac nursing practice. Br. J. Card. Nurs. https://doi.org/10.12968/bjca.2018.13.12.610 (2018).
Google Scholar
-
Kaehne, A. Care integration—from “one size fits all” to person centred care: Comment on “achieving integrated care for older people: Shuffling the deckchairs or making the system watertight for the future?”. Int. J. Heal. Policy Manag. https://doi.org/10.15171/ijhpm.2018.51 (2018).
Google Scholar
-
Franklin, N. C., Lavie, C. & Arena, R. Personal health technology: A new era in cardiovascular disease prevention. Postgrad. Med. https://doi.org/10.1080/00325481.2015.1015396 (2015).
Google Scholar
-
Akinosun, A. S. et al. Digital technology interventions for risk factor modification in patients with cardiovascular disease: Systematic review and meta-analysis. JMIR mHealth uHealth https://doi.org/10.2196/21061 (2021).
Google Scholar
-
Akinosun, A. S. et al. Digital storytelling for cardiovascular disease risk factor modification: A scoping review. Int. J. Heal. Wellness Soc. https://doi.org/10.18848/2156-8960/CGP/v11i01/209-224 (2021).
Google Scholar
-
Grindle M. The power of digital storytelling to influence human behaviour. PhD Thesis, Stirling University (2014).
-
Michie, S., Atkins, L. & West, R. The Behaviour Change Wheel A Guide To Designing Interventions 1st edn. (Silverback Publishing, 2014).
-
Kelly, M. P. & Barker, M. Why is changing health-related behaviour so difficult?. Public Health https://doi.org/10.1016/j.puhe (2016).
Google Scholar
-
Mann, C. J. Observational research methods. Research design II: Cohort, cross sectional, and case-control studies. Emerg. Med. J. 20, 54–60 (2003).
Google Scholar
-
Von Elm, E. et al. The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) statement: Guidelines for reporting observational studies. Ann. Intern. Med. https://doi.org/10.7326/0003-4819-147-8-200710160-00010 (2007).
Google Scholar
-
US Department for Health and Human Services, Centre for Disease Control and Prevention. Principles of Epidemiology in Public Health Practice. Third edition: An introduction (2006).
-
Directorate: Housing and Social Justice Directorate Part of: Communities and third sector. Scottish Index of Multiple Deprivation. 2020v2 Postcode Lookup File—Gov.Scot (2020).
-
World Health Organization, Europe. Nutrition—Body mass index (2021, accessed 22 July 2021); https://www.euro.who.int/en/health-topics/disease-prevention/nutrition/a-healthy-lifestyle/body-mass-index-bmi.
-
British Heart Foundation. Understanding the new cholesterol guidelines. https://www.bhf.org.uk/informationsupport/heart-matters-magazine/medical/ask-the-experts/new-cholesterol-guidelines (2021).
-
National Health Service. Cardiovascular disease. https://www.nhs.uk/conditions/cardiovascular-disease/ (2020).
-
R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing (2020).
-
Mora, S. et al. Determinants of residual risk in 9,251 secondary prevention patients treated with high-versus low-dose statin therapy: The treating to new targets (TNT) study. Circulation https://doi.org/10.1161/circulationaha.111.088591 (2012).
Google Scholar
-
Diabetes and Obesity. https://www.diabetes.co.uk/diabetes-and-obesity.html (2020).
-
Ng, T. P. et al. Age-dependent relationships between body mass index and mortality: Singapore longitudinal ageing study. PLoS ONE https://doi.org/10.1371/journal.pone.0180818 (2017).
Google Scholar
-
Damen, J. A. A. G. et al. Prediction models for cardiovascular disease risk in the general population: Systematic review. BMJ https://doi.org/10.1136/bmj.i2416 (2016).
Google Scholar
-
Teckle, P., Hannaford, P. & Sutton, M. Is the health of people living in rural areas different from those in cities? Evidence from routine data linked with the Scottish Health Survey. BMC Health Serv. Res. https://doi.org/10.1186/1472-6963-12-43 (2012).
Google Scholar
-
Scottish Government. Raising Scotland’s tobacco-free generation: Our tobacco control action plan 2018—gov.scot. https://www.gov.scot/publications/raising-scotlands-tobacco-free-generation-tobacco-control-action-plan-2018/pages/4/ (2018).
-
Brehm, B. J. & D’Alessio, D. A. Environmental factors influencing obesity. MDText.com, Inc. USA (2020).
-
Jin, J. Obesity and the heart. JAMA J. Am. Med. Assoc. https://doi.org/10.1001/jama.2013.281901 (2013).
Google Scholar
-
Cesana, F. et al. Psychological characteristics and total cardiovascular risk relationship in a cohort of 345 consecutive hypertensive patients. High Blood Press. Cardiovasc. Prev. 21, 285–363. https://doi.org/10.1007/s40292-014-0066-z (2014).
Google Scholar
-
Iliodromiti, S. et al. The impact of confounding on the associations of different adiposity measures with the incidence of cardiovascular disease: A cohort study of 296 535 adults of white European descent. Eur. Heart J. https://doi.org/10.1093/eurheartj/ehy057 (2018).
Google Scholar
-
Ginawi, I. A. et al. Association between obesity and cigarette smoking: A community-based study. J. Endocrinol. Metab. https://doi.org/10.14740/jem378e (2016).
Google Scholar
-
Courtemanche, C., Tchernis, R. & Ukert, B. The effect of smoking on obesity: Evidence from a randomized trial. J. Health Econ. https://doi.org/10.1016/j.jhealeco.2017.10.006 (2018).
Google Scholar
-
Kotseva, K. et al. EUROASPIRE IV: A European Society of Cardiology survey on the lifestyle, risk factor and therapeutic management of coronary patients from 24 European countries. Eur. J. Prev. Cardiol. https://doi.org/10.1177/2047487315569401 (2016).
Google Scholar
-
Alkhouli, M. et al. Trends in characteristics and outcomes of hospital inpatients undergoing coronary revascularization in the United States, 2003–2016. JAMA Netw. Open https://doi.org/10.1001/jamanetworkopen.2019.213 (2020).
Google Scholar
Acknowledgements
The NHS Highlands, Cardiac Unit Data-collection Team, without whom there would be no data to analyse. The Caldicott office, NHS Highlands, for the approval of the data for research purpose.
Funding
Project is supported by the European Union’s Interregional VA (INTERREG VA) Programme and managed by the Special European Union Programmes Body (SEUPB) in a trans-European cardiovascular collaboration research project executed through the Eastern Corridor Medical Engineering (ECME), Ireland and supervised by the University of the Highlands and Islands, UK.
Author information
Authors and Affiliations
Contributions
A.S.A. conducted the study and wrote the manuscript. A.S.A. analysed the data, and A.S.A. and W.J. reviewed the analysed data. A.S.A., S.L., and J.W. did a major manuscript review. S.K. and M.G. did a minor manuscript review. A.S.A., S.L., and M.G. coordinated the study.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Reprints and Permissions
About this article
Cite this article
Akinosun, A.S., Kamya, S., Watt, J. et al. Cardiovascular disease behavioural risk factors in rural interventions: cross-sectional study.
Sci Rep 13, 13376 (2023). https://doi.org/10.1038/s41598-023-39451-5
-
Received: 16 August 2021
-
Accepted: 25 July 2023
-
Published: 17 August 2023
-
DOI: https://doi.org/10.1038/s41598-023-39451-5
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.